Spark RDD作为Spark中最核心的数据抽象,是每个大数据开发者必须掌握的基础。简单来说,RDD就是一个可并行计算的、具有容错特性的分布式数据集,它让你像操作本地集合一样处理海量数据。
RDD的三大核心特性
RDD最突出的特性就是弹性、分区和容错。弹性意味着数据可以放在内存或磁盘,分区让数据能分散到集群各节点并行计算,而容错则通过血统机制实现。当某个分区丢失时,系统可以根据依赖关系重新计算,无需人工干预。
如何创建RDD对象
实际开发中主要有两种创建方式。第一种是从外部数据源读取,比如使用()加载HDFS或本地文件。第二种是将程序中的集合并行化,调用()把数组或列表转成RDD。对于小规模测试数据,后者非常方便快捷。
转换与行动操作详解
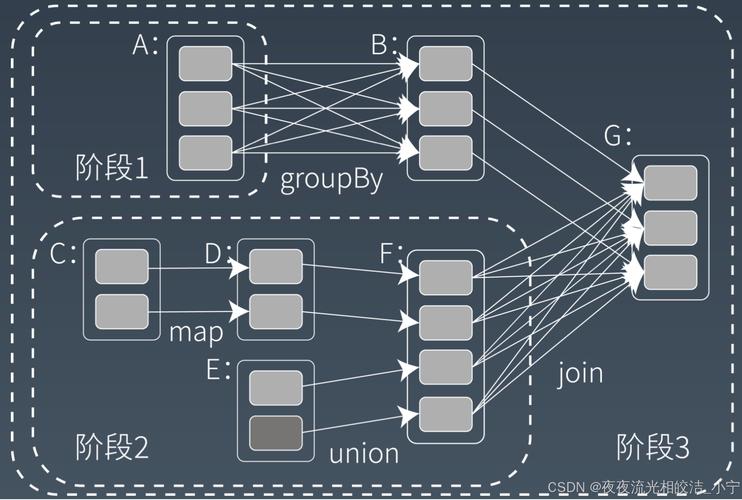
RDD的操作分为转换和行动两类。转换操作如map、、等,它们只是定义计算逻辑,并不会立即执行。而行动操作如count、、会触发真正的计算。理解这个区别,就能写出高效的Spark作业。
持久化策略如何选择
当多个行动需要重复使用同一个RDD时,使用()或cache()可以避免重复计算。根据内存大小和计算成本,可以选择、等不同级别。对于迭代算法或多次查询的场景,合理持久化能大幅提升性能。
你在实际项目中使用RDD时,遇到过哪些性能优化的难题?欢迎在评论区分享你的经验,也别忘了点赞和转发给需要的朋友。