作为 Spark生态中的图计算引擎,完美融合了图处理与分布式数据处理的优势。它基于RDD模型,为大规模图数据提供了高效、容错的迭代计算能力。无论是社交网络分析还是知识图谱构建,都能显著降低开发门槛。
性能怎么样
的核心优势在于其内存计算与弹性分布式数据集(RDD)的深度整合。它将图数据以顶点和边的RDD形式存储,利用Spark的缓存机制避免重复计算。对于、连通分量等迭代算法,能够将中间结果保存在内存中,相比传统的框架,性能可提升数倍甚至数十倍。
适合什么场景
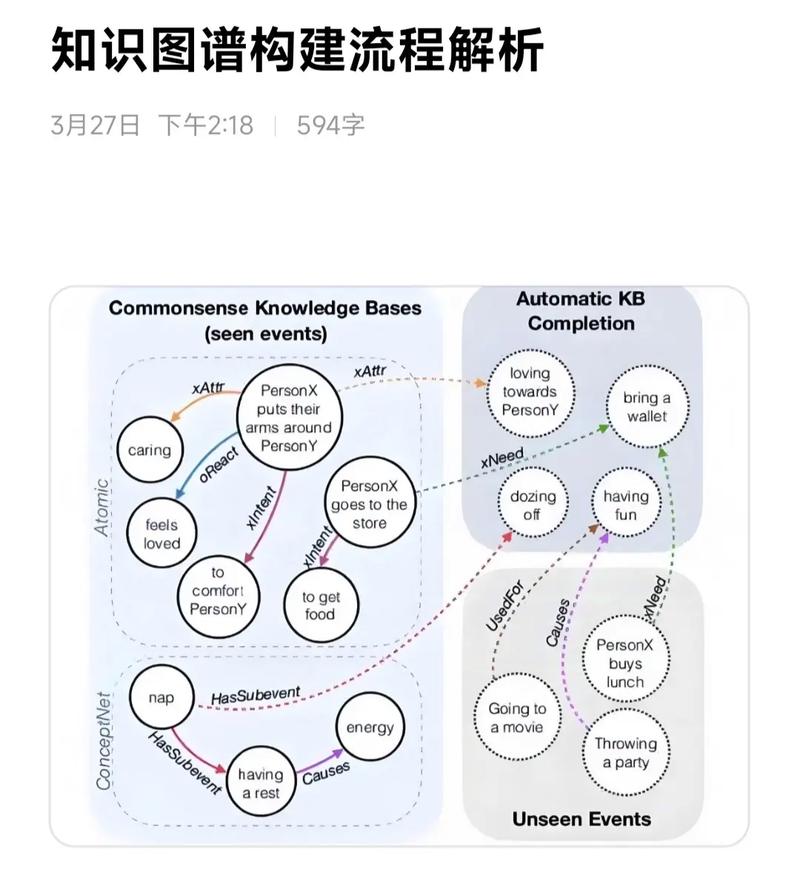
从金融风控中的欺诈环检测到推荐系统的用户行为图谱,在需要分析实体关联性的领域表现突出。例如电信运营商利用识别通话网络中的异常群组,生物信息学研究者用它分析蛋白质相互作用网络。只要问题可以抽象为图结构,且数据量超过单机内存,就是理想选择。
与对比如何
与 这类纯图计算框架相比,最大的特色是同时支持图计算和标准Spark数据处理。你可以先用Spark SQL清洗数据,再无缝转换为图进行算法分析,最后将结果写回做统计。而需要额外的数据转换代码。不过在超大规模图(十亿级边)上可能略有性能优势。
你是否在实际项目中遇到过图数据处理的性能瓶颈?欢迎在评论区分享你的经验,点赞让更多开发者看到这篇干货!