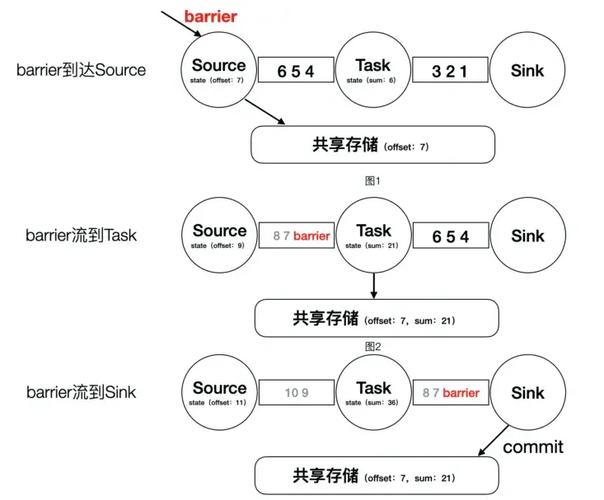
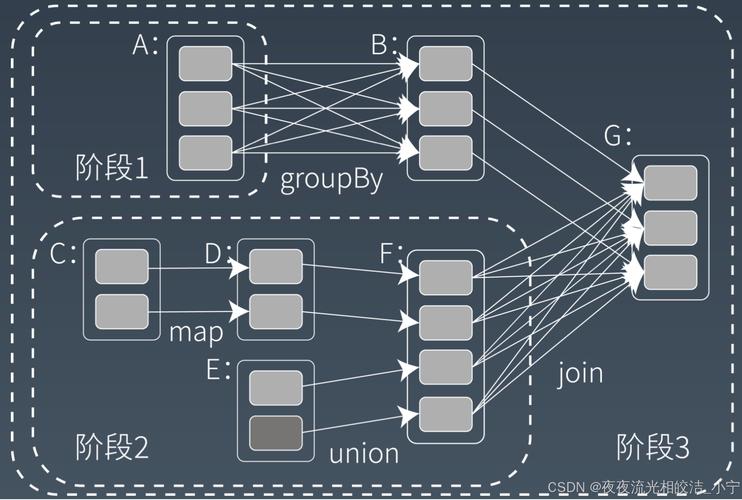
Spark 的微批处理是把实时流入的数据按时间切片,形成小批量数据后再交给Spark引擎处理。这种方式既保留了批处理的稳定高效,又能达到秒级响应,是很多公司做实时计算的首选方案。
微批处理原理是什么
微批处理就是把连续不断的数据流切分成固定时间窗口的小批次,每个批次内部当作RDD来处理。用户通过设置batch 参数决定切片大小,比如5秒一个批次,系统就会每5秒提交一次计算任务。这种设计让开发者可以用批处理的API直接写流式逻辑,大幅降低学习门槛。
Spark 延迟有多低
延迟主要取决于批次间隔和处理耗时。如果每个批次能在间隔时间内完成,端到端延迟基本等于批次间隔。生产环境常用1到5秒的间隔,配合高性能集群能做到2秒内输出结果。需要注意的是,当数据突然暴增时,处理时间可能超过间隔时间,延迟就会逐渐累积。
如何优化微批处理性能
优化要从并行度和资源分配入手。首先合理设置分区数,让每个分区数据量适中,避免数据倾斜。其次开启背压机制,让系统自动调节接收速率,防止崩溃。还可以使用直连方式读取Kafka,消除多余的事务开销。内存方面,开启堆外内存和序列化缓存能显著减少GC停顿。
常见调优参数有哪些
关键参数包括spark…开启背压,spark..kafka.限制单分区速率,spark.sql..控制并行度。批次间隔建议从5秒开始测试,观察处理耗时和延迟曲线。如果处理耗时超过间隔的80%,就要调大间隔或增加计算资源。
你在生产环境中遇到过微批处理的延迟问题吗?欢迎在评论区分享你的调优经验,点赞收藏让更多朋友看到这篇文章。