Flink on YARN是生产环境中最常见的部署模式之一,但很多团队只关注业务逻辑,忽略了底层调优,导致资源浪费、任务反压甚至频繁失败。调优的核心在于平衡内存、并行度和容错机制,让集群资源被高效利用。下面从三个最实际的切入点展开。
内存参数怎么配
和的内存划分直接决定任务稳定性。通常分配1-2GB堆内存加少量堆外,而需要精细设置:...size决定总进程内存,减去JVM元空间和开销后,剩余分为框架堆、任务堆、网络缓冲、托管内存和堆外。常见错误是把托管内存设得过大,导致网络缓冲不足引发反压。建议托管内存占TM总内存的30%-40%,并开启...-为算子分配比例。
堆外内存容易被忽略,但状态后端和网络通信都依赖它。..off-heap.size应设为托管内存的20%-30%,同时监控容器实际使用量,避免被YARN kill。对于大状态作业,建议将..jvm-.min和max设为相同值,比如512MB,防止JVM动态调整时波动。调参后务必用Flink UI的“”面板验证各区域分配是否合理。
并行度如何定
并行度不是越大越好。每个并行子任务至少需要一个线程和一个网络缓冲区,过高的并行度会导致大量小数据包、频繁上下文切换,反而降低吞吐。经验法则是:源端并行度对齐Kafka分区数,中间算子根据数据量调整,Sink并行度匹配下游写入能力。同时考虑YARN容器限制,单个的slot数乘以并行度不应超过节点CPU核心数。
一个常见调优场景是数据倾斜。如果某个key的数据量特别大,单纯增加并行度没用,需要先做两阶段聚合或打散key。另外,动态并行度调整要配合slot group,避免不同算子争抢slot。建议先用小数据集测试,观察每个的处理记录数和延迟,找到吞吐曲线的拐点。比如从2并行度开始,每次翻倍,直到吞吐不再线性增长。
容错机制怎么调
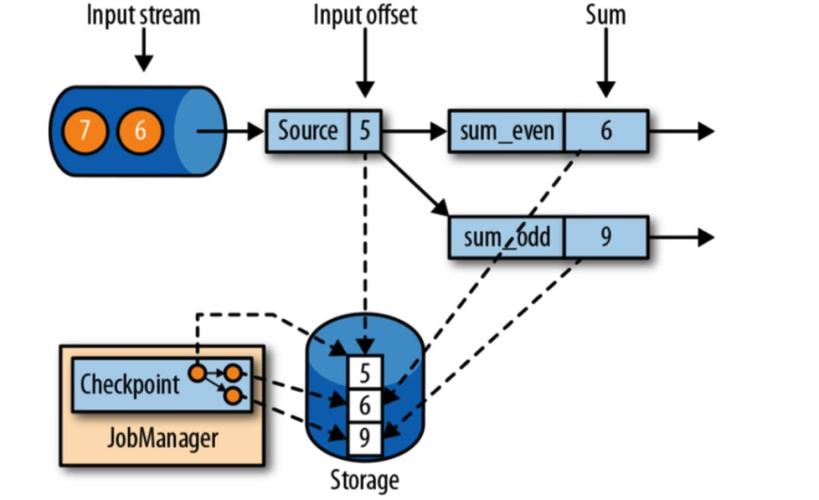
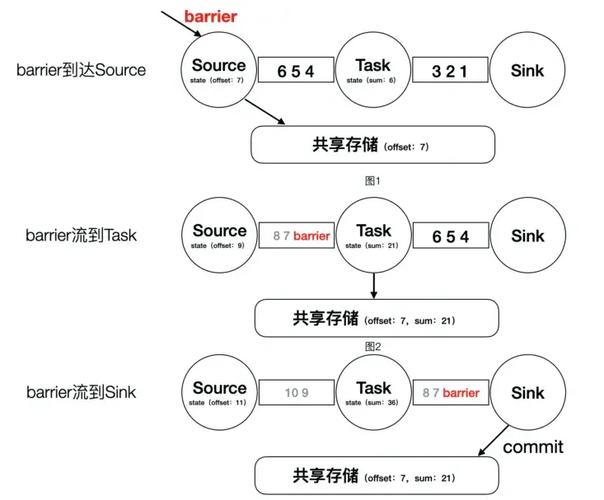
检查点()的参数直接影响任务恢复速度和资源消耗。..不宜过短,否则频繁flush导致IO飙升;也不宜过长,会使重启后追数据耗时太久。一般生产环境设为1-5分钟。同时设置..min-pause为间隔的一半,防止检查点积压。对于大状态作业,务必开启增量检查点,能减少90%以上的传输量。
失败重启策略建议用fixed-delay,并设置合理重试次数。还要调整YARN的超时参数:yarn.----控制多长时间内的失败算同一轮重试,yarn..am.max-限制最大尝试次数。另外,给留出足够的堆外内存用于状态恢复时的临时数据,否则恢复阶段容易OOM。最后,记得开启state....flush,避免重启时丢失未刷新的数据。
你在Flink on YARN调优中踩过哪些“隐形坑”?欢迎在评论区分享经历,一起避坑。觉得有用请点赞转发,让更多人看到。