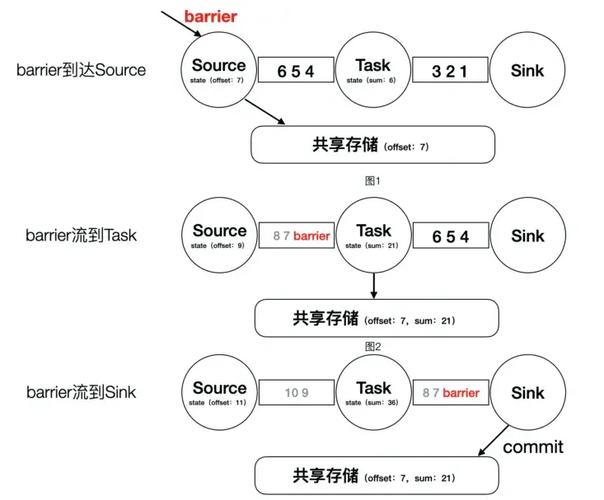
Flink的机制是流处理中保证数据一致性和容错能力的关键。简单来说,它就像给运行中的计算任务拍了一张快照,记录下每个算子的状态和输入位置。当任务意外挂掉时,就能从最近一次成功的快照恢复,就像游戏存档读档一样。理解这个机制,是掌握Flink稳定性的第一步。
如何实现精确一次语义
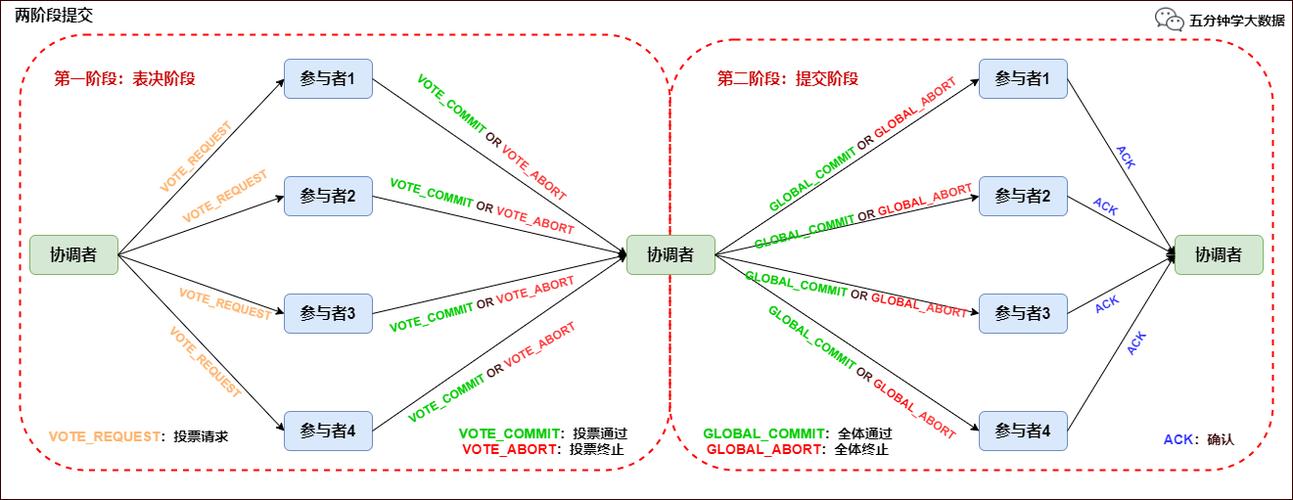
精确一次(-Once)是机制最吸引人的特性。它通过两阶段提交协议和分布式快照算法(-)协同工作。算子插入特殊的分界线(),随着数据流向下游传递。当所有算子都完成对齐后,整个快照才算成功。这样一来,即便发生故障重启,每条记录也只会被处理一次,不会重复也不会遗漏。
与区别是什么
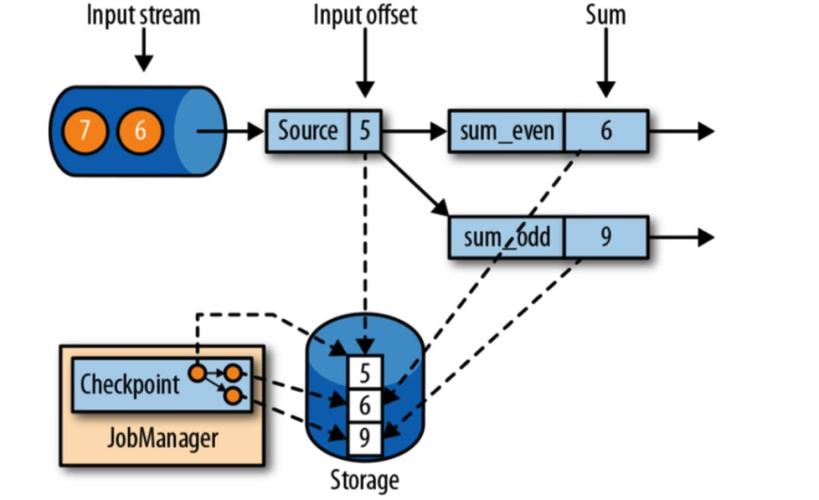
很多初学者容易把和搞混。是Flink自动触发的轻量级快照,主要用于故障恢复,由系统管理生命周期。而是用户手动触发的,需要保存到外部持久化存储,常用于版本升级、逻辑修改或集群迁移。简单记:保命,搬家。
如何优化性能降低成本
频繁做确实会影响作业吞吐量。建议调整“检查点间隔”到合理范围,比如秒级或分钟级。同时开启异步快照和增量,前者让数据写入不阻塞计算,后者只记录变更部分,大幅减少传输量。另外,选对状态后端也很关键,适合大状态,只适合小规模测试。合理配置后,对性能影响可控制在5%以内。
看到这里,你是否遇到过因超时导致作业频繁失败的窘境?欢迎在评论区分享你的调参经验,点赞让更多看到这份避坑指南。