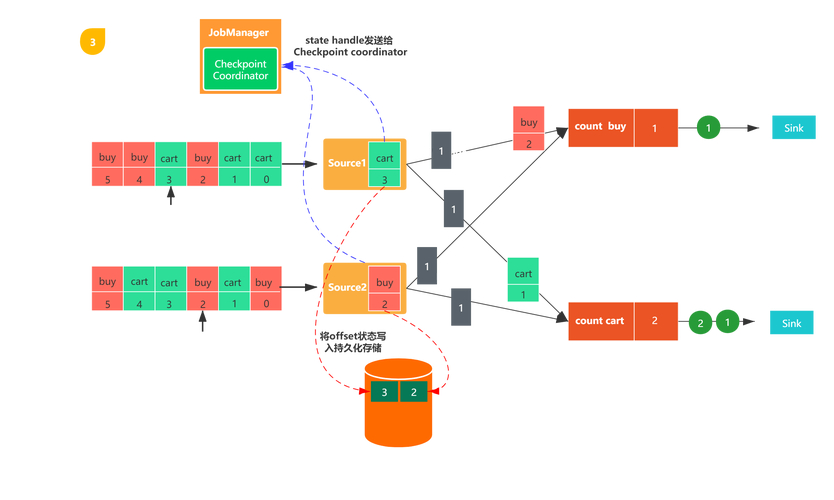
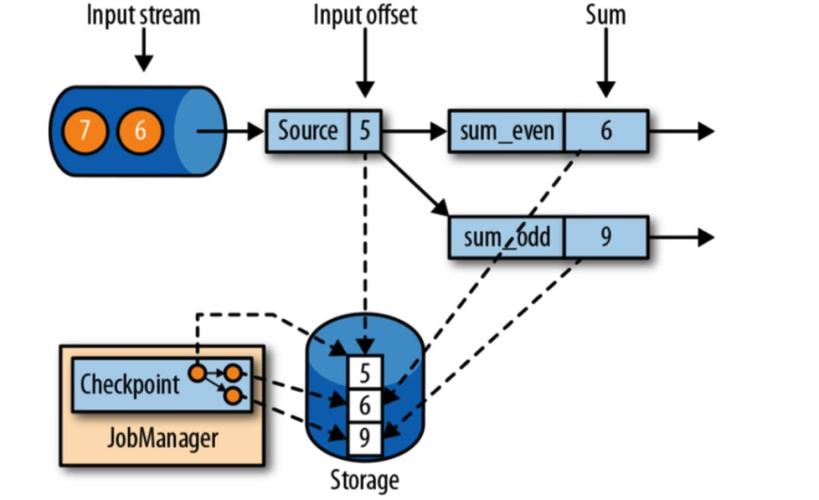
Flink的-Once语义是流处理中最关键也最容易被误解的概念。它保证每条数据只被处理一次,即使发生故障也不会重复或丢失,这是实现数据准确性的基石。很多开发者在实际项目中会遇到“明明开启了精准一次,数据还是对不上”的困惑,其实根源往往在于对底层机制理解不深。
如何保证精准一次
Flink主要依靠轻量级检查点和两阶段提交协议来实现-Once。检查点定期保存算子状态,故障时从最近检查点恢复。而两阶段提交则让结果数据在预提交阶段暂存,等检查点完成后再统一提交到外部存储。这两个机制配合,才能在下游系统也支持事务的前提下达成端到端的精准一次。
端到端精准一次有哪些坑
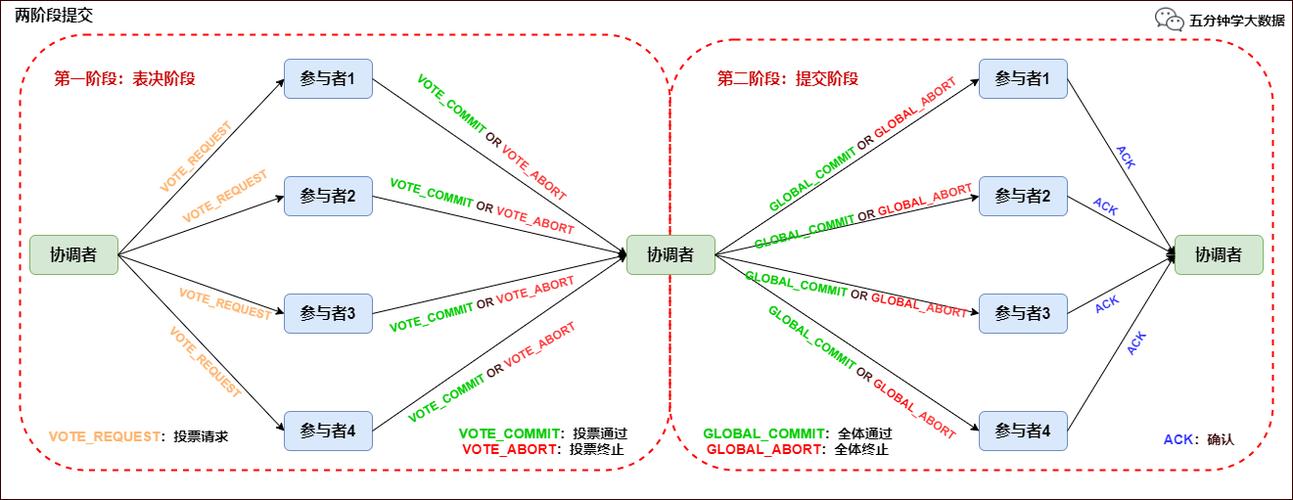
常见的坑包括Kafka事务超时、外部存储不支持回滚、以及任务重启后的状态不匹配。比如Kafka 的事务超时如果小于Flink检查点间隔,就会频繁报错。还有不少团队只开启了内部精准一次,却忽略了Sink端的事务配置,导致最终写入数据库时出现重复数据。这些细节往往在压测时才会暴露。
如何优化精准一次性能
精准一次必然带来额外开销,优化关键是减少检查点耗时和事务等待时间。建议调整检查点间隔为30秒到1分钟,并启用异步快照和增量检查点。对于高吞吐场景,可以将Sink的事务隔离级别降到读已提交,或者改用幂等写入方式替代两阶段提交。实际生产中,很多业务允许最终一致,没必要所有流程都强求精准一次。
看完以上内容,你在实际项目中被Flink的重复或丢失数据坑过吗?欢迎在评论区分享你的踩坑经历和解决方案。