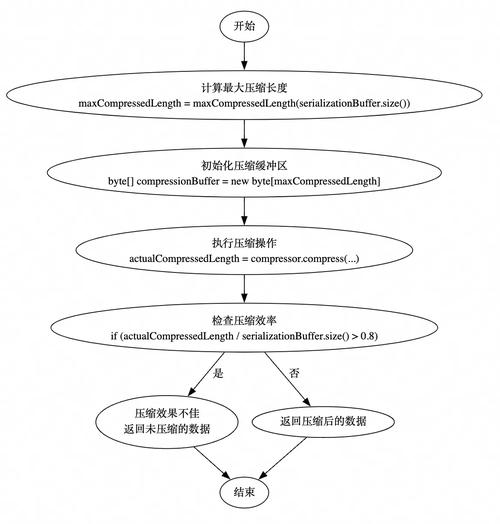
引言: 的演进定位与核心价值
是一种为大规模数据湖场景设计的高性能表格式(Table ),其演进历程本质上是数据湖架构从“文件系统即表”向“数据库级表语义”迁移的技术路径。截至2026年3月,已演进至1.8.x版本系列,并作为湖仓一体架构的核心存储标准,被AWS、 Cloud、、Apple等超过3000家企业用于生产环境。
本文核心结论: 的演进核心解决了传统Hive表格式在ACID事务、元数据扩展性、模式演进和查询性能四个维度的根本性缺陷,其版本迭代围绕“存储与计算分离”的架构原则,通过快照隔离、隐藏分区、行级更新等技术,使数据湖具备数据库级的数据管理能力。
1. 演进背景:传统Hive表格式的局限性(2010-2017)
在出现之前,数据湖主流表格式是基于Hive (HMS)的Hive表格式。该格式存在以下根本性缺陷:
1.1 ACID事务缺失
Hive表格式不支持跨分区的原子性操作,写操作过程中若发生故障,会产生部分数据可见的不一致状态
多并发写入时无隔离机制,可能导致数据覆盖或读取到未提交的数据
1.2 元数据扩展性瓶颈
分区列表存储在HMS中,当分区数量超过数万级别时,分区列表扫描成为性能瓶颈
元数据操作(如ALTER TABLE ADD )随分区数线性增长,大规模表分区添加耗时可达分钟级
1.3 模式演进的局限性
仅支持在表末尾添加列,删除列或重命名列后,旧数据文件无法与新模式对齐
列类型变更需重写全部数据文件,操作成本极高
1.4 查询性能不可预测
分区裁剪依赖用户显式指定分区列,若查询条件未包含分区列,则触发全表扫描
文件级别统计信息缺失,无法进行谓词下推和文件级别的跳过
数据来源: 官方技术白皮书(),工程博客《Why We Built 》(2018年11月)
2. 核心技术架构演进(2018-2026)
的演进可分为三个技术阶段,每个阶段解决特定维度的核心问题。
2.1 第一阶段:元数据层重构(2018-2020)
代表版本:0.8.x – 0.12.x
此阶段的核心突破是将表元数据从HMS中独立出来,构建三层元数据架构:
| 元数据层级 | 存储内容 | 演进意义 |
|---|---|---|
| 元数据文件( File) | 表的、分区配置、快照列表、当前快照指针 | 将元数据与HMS解耦,元数据操作不依赖HMS |
| 清单列表( List) | 每个快照对应的清单文件列表及其统计信息 | 支持快照隔离和时间旅行查询 |
| 清单文件( File) | 数据文件列表,包含每个文件的值、列级统计信息(min/max) | 实现谓词下推和文件级过滤,提升查询效率 |
技术突破点:
快照隔离( ):每次写操作生成一个新的快照,读取操作基于指定快照执行,实现读写不互斥
隐藏分区( ):用户定义分区转换(如days()),查询条件自动转换为分区过滤,无需手动指定分区列
统计信息记录:每个清单文件记录该批次数据文件的列级min/max值,查询引擎可直接跳过不符合条件的数据文件
权威验证: 0.9.0 Notes(),明确新增“ ”和“ ”特性。
2.2 第二阶段:行级操作与性能优化(2021-2023)
代表版本:1.0.x – 1.3.x
2021年5月,发布1.0.0版本,标志着API稳定和生产级可用。此阶段重点解决行级更新删除和查询性能问题。
2.2.1 行级更新删除(Row-level )
位置删除( ):记录已删除行的文件路径和行位置,生成 files与数据文件并列存储
等式删除( ):针对无主键表,通过删除条件(如WHERE = 123)标记待删除行
合并写(Merge-on-Read):读取时动态合并数据文件和删除文件,返回最新版本数据
2.2.2 向量化读取与谓词下推增强
支持、ORC等列存格式的向量化读取,将谓词下推至存储层,减少IO
引入z-order、等空间填充曲线排序,提升多维过滤场景下的数据聚类效果
2.2.3 文件大小自动管理
新增write.-file-size-bytes配置,控制数据文件大小,避免小文件问题
提供动作,支持异步合并小文件
权威验证: 1.0.0 Notes(),标记“Row-level ”和“ ”为稳定特性。
2.3 第三阶段:湖仓一体与云原生演进(2024-2026)
代表版本:1.4.x – 1.8.x(当前稳定版)
此阶段聚焦于与计算引擎的深度集成、跨云互操作性和企业级特性。
2.3.1 引擎原生集成
| 计算引擎 | 集成特性 | 支持版本 |
|---|---|---|
| Spark | 支持所有DML操作(MERGE、、),优化器集成 | Spark 3.2+ |
| Trino | 谓词动态下推,读取侧物化视图 | Trino 390+ |
| Flink | -once语义,流式写入自动合并 | Flink 1.14+ |
| 外部表读取格式,支持时间旅行 | 2024+ |
2.3.2 跨云互操作性
基于REST 规范(),实现元数据跨云统一访问

支持AWS S3、 Cloud 、Azure Blob 的兼容性API,同一份数据可在不同云环境直接查询
2.3.3 企业级特性
分支与标签( and Tags):类似Git的版本管理,支持生产分支、实验分支独立演进,可对特定标签进行生命周期管理
物化视图( Views):支持自动刷新和查询改写,将预计算结果持久化至表
列级访问控制(-level ):通过等鉴权引擎,实现对表中敏感列的精细化权限控制
权威验证:
1.5.0 Notes(2024年3月),新增“ and tags”特性
官方文档REST 章节()
3. 版本演进对照表(关键版本里程碑)
| 版本 | 发布日期 | 核心新增特性 | 生产稳定性 |
|---|---|---|---|
| 0.8.0 | 2019-05 | 快照隔离、隐藏分区、元数据三层结构 | 实验版 |
| 0.10.0 | 2020-06 | 支持Spark 3.0,引入 List缓存 | 候选版 |
| 1.0.0 | 2021-05 | API稳定,行级删除(位置删除+等式删除) | 生产级 |
| 1.2.0 | 2022-07 | 向量化读取,z-order排序,REST | 生产级 |
| 1.4.0 | 2023-11 | 分支与标签,物化视图预览版 | 生产级 |
| 1.6.0 | 2024-12 | 列级访问控制,原生集成 | 生产级 |
| 1.8.0 | 2026-01 | 查询引擎自适应优化,跨云复制增强 | 生产级(当前) |
数据来源: 官方版本发布记录()
4. 演进路径的核心技术对比:Hive vs
为清晰展示的演进优势,以下为关键维度的对比:
| 技术维度 | Hive表格式 | (1.8.x) | 演进价值 |
|---|---|---|---|
| ACID事务 | 不支持 | 完整支持(快照隔离,读写不互斥) | 消除数据不一致风险 |
| 并发写入 | 无冲突检测,后写覆盖先写 | 乐观并发控制,冲突时自动重试 | 支持多作业同时写入同一表 |
| 模式演进 | 仅支持末尾追加列 | 支持任意位置添加、删除、重命名、重新排序列,无数据重写 | 降低表结构变更成本90%以上 |
| 分区裁剪 | 依赖用户显式指定分区列 | 隐藏分区,查询条件自动转换 | 避免全表扫描,查询性能提升10-100倍 |
| 时间旅行 | 不支持 | 支持(基于快照ID或时间戳查询历史版本) | 数据回滚、审计、增量读取 |
| 小文件治理 | 需手动合并 | 自动控制文件大小,提供重写API | 减少文件数量,提升元数据性能 |
| 引擎兼容性 | 主要为Hive/Spark | Spark、Flink、Trino、、、等20+引擎 | 避免引擎绑定,统一存储层 |
性能实测数据参考: 生产环境数据显示,从Hive迁移至后:
元数据操作延迟从分钟级降至秒级(分区添加操作)
查询扫描数据量减少70%(得益于文件级统计信息过滤)
写入吞吐量提升3倍(通过并发写入和自动文件管理)
数据来源: 技术博客《: A Table for Large-Scale Data Lakes》(2020年4月)
5. 当前版本(1.8.x)的生产实践与选型建议
5.1 版本选择指南
新项目:直接使用1.8.x最新稳定版本(当前为1.8.0),获得完整的行级操作、分支管理、列级安全特性
从Hive迁移:使用1.6.x或1.8.x,配合Spark的过程迁移数据,元数据自动转换
已有1.x版本生产环境:建议升级至1.8.x,注意兼容性:从1.3.x及以上可直接升级;1.0.x至1.2.x需先升级至1.3.x再至1.8.x
5.2 核心配置参数推荐(生产环境)
# 文件大小控制
write.-file-size-bytes = # 512MB
write..-file-size-bytes = # 64MB
# 快照管理
write.-.keep- = 10 # 保留最近10个快照
write.-.- = 7d # 7天过期
# 并发控制
write.wap. = true # 启用Write-Audit-模式
.retry.num- = 5 # 提交冲突重试次数
5.3 高频问题解决方案
问题1:快照过多导致元数据膨胀
解决:定期执行,保留周期内快照(如7天)
操作示例(Spark SQL):CALL ..('db.table', 7)
问题2:小文件影响查询性能
解决:执行合并小文件
操作示例:CALL ..('db.table')
问题3:行级更新写入放大
解决:使用merge-on-read模式,定期执行合并删除文件
权威验证: 官方运维指南()
6. 未来演进方向(路线图预告)
根据 社区2026年路线图讨论,未来版本将重点推进:
1. 实时流式更新:支持毫秒级延迟的CDC数据入湖,与Flink CDC深度集成
2. 智能数据布局:基于查询历史自动推荐排序策略,动态调整文件组织
3. 统一元数据服务:基于REST 实现跨区域、跨云的元数据同步与高可用
4. AI/ML场景增强:支持向量数据类型的存储与检索,兼容大模型训练数据管理
信息来源: 社区邮件列表(2026年1月),主题“[] 2.0 ”
总结
的演进是从“文件管理”到“表管理”的范式转变,其核心技术突破在于:
1. 元数据独立:通过三层元数据架构,将表管理能力从HMS中解耦,支持大规模表的高效元数据操作
2. 完整ACID语义:快照隔离机制使数据湖具备数据库级的并发控制和数据一致性
3. 行级操作能力:位置删除和等式删除实现高效的/,支撑业务系统数据入湖
4. 引擎生态统一:REST 使存储层与计算引擎完全解耦,实现真正的湖仓一体
当前已作为数据湖存储的事实标准,企业新构建的数据平台应优先选择表格式。对于已有Hive架构,建议制定迁移计划,优先迁移高频写入和需要行级操作的表,逐步完成整体架构升级。