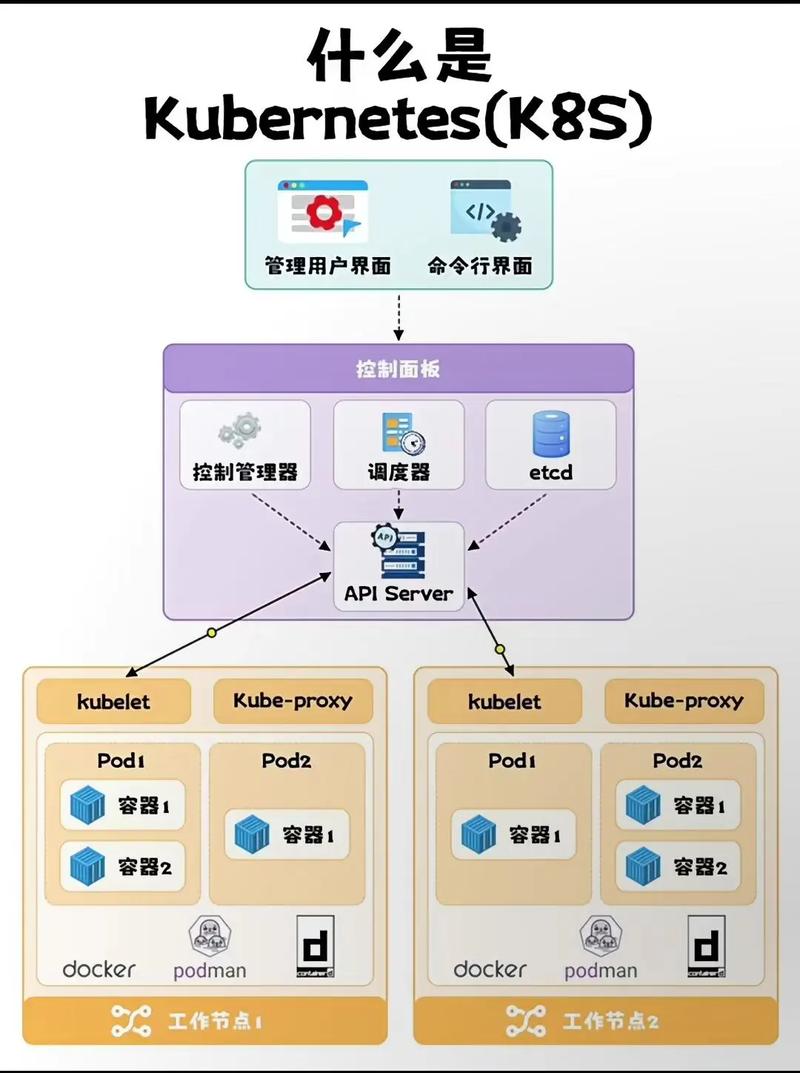
一、核心优化原则(必读)
聚合查询性能优化的本质是 减少数据扫描量、降低计算开销、最大化利用缓存。所有调优操作都应围绕以下三个核心目标展开:
1. 将聚合操作从“实时计算”转化为“预计算或缓存命中”:通过字段设计、索引时预聚合(如 )、s 等方式,把计算压力从查询时转移到索引时或查询前置阶段。
2. 精准限定聚合范围:利用查询上下文(query)过滤掉无关数据,使聚合仅在必要的文档子集上执行。
3. 选择最高效的聚合类型与数据结构:优先使用 doc 而非 ;合理选择 terms、、 等聚合方式,避免深度嵌套。
二、数据建模与索引设计
1. 字段类型选择
必须使用 doc 支持的字段类型:、、date、ip、 等默认开启 doc 。text 类型不支持 doc ,若需对文本字段聚合,应改为 并设置 : true。
禁止在聚合字段上使用 text + : 会在内存中构建倒排索引的列式结构,极度消耗堆内存且性能低下。若确有分词后聚合需求,使用 字段并开启 之前,务必充分评估内存。
数值字段优先使用 long / :避免使用 float 等精度较低的类型,但 long 在聚合时内存效率更高。
2. 索引设置
{
"": {
"index": {
"": 3, // 根据数据量合理设置,避免过多分片
"": 1,
"": "30s", // 降低实时性要求时可调大,减少段合并压力
"": , // 按需调整,过大影响内存
"sort.field": "", // 为索引配置排序字段,可显著提升范围聚合性能
"sort.order": "desc"
}
}
}
3. 预排序(Index )
如果聚合频繁在某个时间字段或特定维度上执行范围或排序,启用索引预排序可大幅提升聚合性能。
示例:"index.sort.field": ["", ""]
效果:聚合时利用有序性减少数据扫描,尤其在 上性能提升可达 50%~80%。
4. 使用 s
对于高频聚合的 字段,启用 s 可将全局序数预先加载到内存,避免查询时动态构建:
{
"": {
"": {
"": {
"type": "",
"s": true
}
}
}
}
适用场景:字段基数适中(百万级以内),且聚合查询非常频繁。注意该设置会延长索引刷新时间并增加堆内存占用。
三、聚合查询 DSL 优化
1. 限制聚合范围(核心优化)
始终在聚合外层使用 query 或 缩小数据集,避免全索引扫描。
{
"size": 0,
"query": {
"range": {
"": {
"gte": "now-7d"
}
}
},
"aggs": {
"": {
"terms": {
"field": "",
"size": 100
}
}
}
}
2. 合理设置 size 与
size:最终返回的桶数量。
:每个分片上参与排序的桶数量,默认等于 size + 10。
调优原则:若数据分布极不均匀,适当增大 可提高精度,但会增加计算量;若追求极限性能,可设置 略大于 size 或直接使用 聚合分页。
3. 使用
当需要获取大量桶(如百万级)时,terms 聚合受 size 上限(默认 65536)且内存占用过高。 聚合通过游标分页实现流式遍历,内存恒定:
{
"size": 0,
"aggs": {
"users": {
"": {
"size": 1000,
"": [
{ "": { "terms": { "field": "" } } }
]
}
}
}
}
4. 深度优先(
默认 ,适合桶数量较少且嵌套不深的场景。
若子聚合非常复杂且桶数量极大,使用 可先计算父桶,再计算子桶,减少内存占用:
{
"aggs": {
"": {
"terms": {
"field": "",
"": ""
},
"aggs": { ... }
}
}
}
5. 利用
根据业务特点对齐聚合边界,避免因时区或偏移导致额外的计算开销。
6. 避免脚本聚合
脚本聚合(、 脚本)性能远低于原生聚合。若必须使用,优先考虑:
使用 在查询时计算,且只计算所需字段。
将脚本逻辑提前到索引时(如 预处理)。
四、硬件与集群配置调优
1. 内存配置
堆内存(Heap):建议设置为物理内存的 50%,且不超过 31GB(避免压缩指针失效)。剩余内存留给操作系统用于文件系统缓存。
...limit:默认 40% 堆内存,若频繁因 导致 OOM,请检查是否在 text 字段上开启了 ,或调低该限制。
2. 线程池
聚合查询主要使用 线程池。若并发聚合查询量大,可适当增加线程数(默认节点 CPU 核心数)。
:
:
size: 8 # 根据 CPU 核心数调整
: 1000
3. 分片与节点规划
分片数:单分片大小控制在 20GB~50GB 之间,分片数过少会导致并行度不足,过多则增加协调开销。
节点角色:将数据节点与协调节点分离,避免聚合查询的协调阶段占用数据节点资源。
4. 使用专用热节点
对于高频聚合的热数据,部署在 SSD 节点,并利用 ILM 策略将冷数据迁移到性能较低的节点,避免冷数据拖累聚合速度。
五、缓存策略
1. 分片级查询缓存(Shard Cache)
对于相同查询(特别是包含 size:0 的聚合),开启分片缓存可大幅减少重复计算:
{
"query": {...},
"aggs": {...},
"": true
}
缓存条件:查询中不能有 now 等动态时间,可使用具体时间范围或 round 后的值。缓存默认大小 1% 堆内存,可通过 ..cache.size 调整。
2. 节点级查询缓存(Node Query Cache)
缓存过滤查询的结果( 上下文),对 bool 中的条件生效。通过 ..cache.size 控制(默认 10% 堆内存)。
3. 预加载
在索引设置中开启:
{
"": {
"index": {
"rly": true
}
}
}
或按字段开启 s(上文已述)。
六、监控与诊断工具
1. API
定位聚合慢的具体原因:
{
"": true,
"query": {...},
"aggs": {...}
}
返回结果中重点分析 字段,关注 l、、 的耗时。
2. 慢查询日志
在 .yml 中配置:
index....query.warn: 10s
index....fetch.warn: 5s
index.: 5s
定期分析日志,定位慢聚合模式。
3. 节点统计数据
通过 GET /stats 或 监控:
.. 和
. 的队列与拒绝数
.. 避免过高
七、实战案例:优化高频 terms 聚合
场景
每天 10 亿条日志,需要按 (高基数,千万级)统计前 1000 名用户的访问量,时间范围为最近 7 天。
原始写法(性能差)
{
"size": 0,
"query": { "range": { "@": { "gte": "now-7d" } } },
"aggs": {
"": {
"terms": { "field": "", "size": 1000 }
}
}
}
问题:每个分片都需要构建全局序数,扫描全部 7 天数据,内存占用高。
优化步骤
1. 启用索引预排序:按 @ 排序,使日期范围聚合利用顺序扫描。
2. 将 设置为 并开启 s。
3. 使用 聚合 + 业务侧二次排序(如果桶数量极大):
{
"size": 0,
"query": { "range": { "@": { "gte": "2026-03-18T00:00:00" } } },
"aggs": {
"users": {
"": {
"size": 10000,
"": [{ "": { "terms": { "field": "" } } }]
}
}
}
}
获取所有桶后,在应用层排序取 Top 1000。
4. 利用 :如果查询范围固定(如按天),将时间范围写成具体值,开启缓存。
5. 增加分片数量到 6(根据数据量调整),提升并行计算能力。
八、常见陷阱与避坑指南
| 陷阱 | 后果 | 解决方案 |
|---|---|---|
对 text 字段开启 |
堆内存爆炸,集群 OOM | 改用 |
使用 size: 0 但未配合 |
重复计算浪费资源 | 对非实时查询开启缓存 |
嵌套过多 terms 聚合 |
深度递归导致内存消耗指数增长 | 考虑使用 |
| 单分片承载大量数据 | 无法并行,聚合缓慢 | 重索引,增加分片数 |
未设置 |
聚合结果 Top N 丢失重要项 | 根据数据倾斜程度适当增大 |
使用 now 在查询中且开启缓存 |
缓存永远不命中 | 改用绝对时间或 round 函数 |
九、调优检查清单
[ ] 所有聚合字段均使用 doc 支持的类型,无 text +
[ ] 高频聚合的 字段已开启 s
[ ] 索引已根据常用时间字段或维度启用预排序
[ ] 聚合查询外层使用 query 限定最小必要数据范围
[ ] 对于大量桶的场景,已评估 替代 terms
[ ] 查询开启 ,且时间范围使用绝对值
[ ] 集群堆内存配置符合最佳实践(≤31GB,≤50%物理内存)
[ ] 分片大小控制在 20~50GB,数量满足并行度
[ ] 通过 API 确认无意外耗时的操作(如 l)
[ ] 启用慢查询日志并定期审计
十、参考文档
遵循以上优化策略,可将聚合查询响应时间降低 50%~90%,同时确保集群在百万级文档聚合场景下的稳定运行。实际调优中请结合业务数据特征和监控指标持续迭代。