数据湖火了这么多年,但很多企业实际用下来才发现,它并不能完全替代数据仓库。特别是在需要高效、稳定的报表和可视化分析场景里,数据仓库依然有着不可撼动的地位。
数据湖与数据仓库并非二选一

很多人误以为数据湖是更先进的替代品,这其实是个误区。数据湖存储的是原始数据,格式多样,就像一个大仓库把各种货物原封不动地放进去。而数据仓库存储的是经过清洗、加工好的数据,像超市货架上整齐排列的商品。
在实际的企业架构中,两者更多是协同关系。数据湖作为数据的中转站和存储池,而数据仓库则专注于为前端报表和BI工具提供高性能服务。用数据仓库跑每日的经营报表,响应速度通常在秒级,这是直接查询数据湖很难做到的。
Hudi 让数据湖具备了处理能力
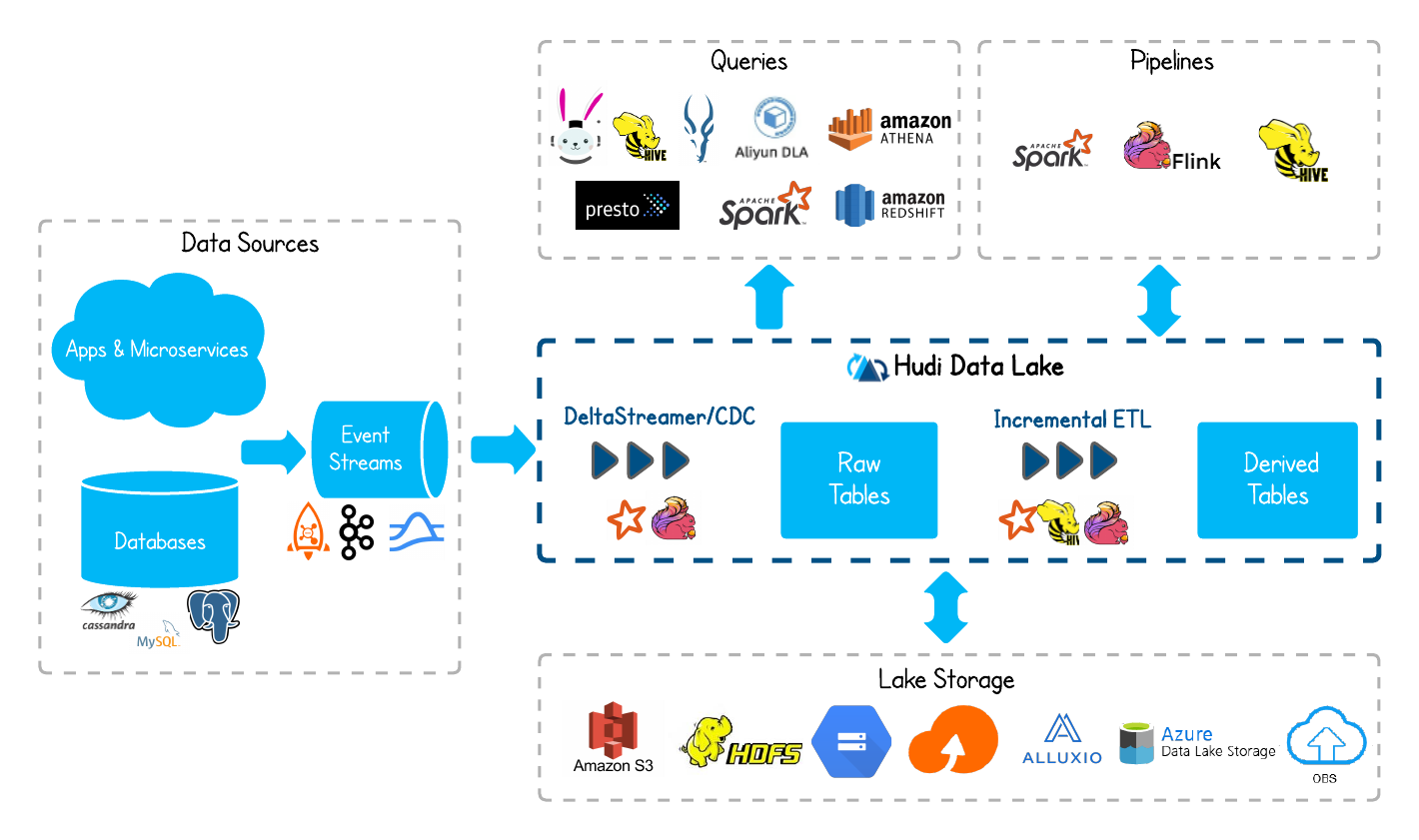
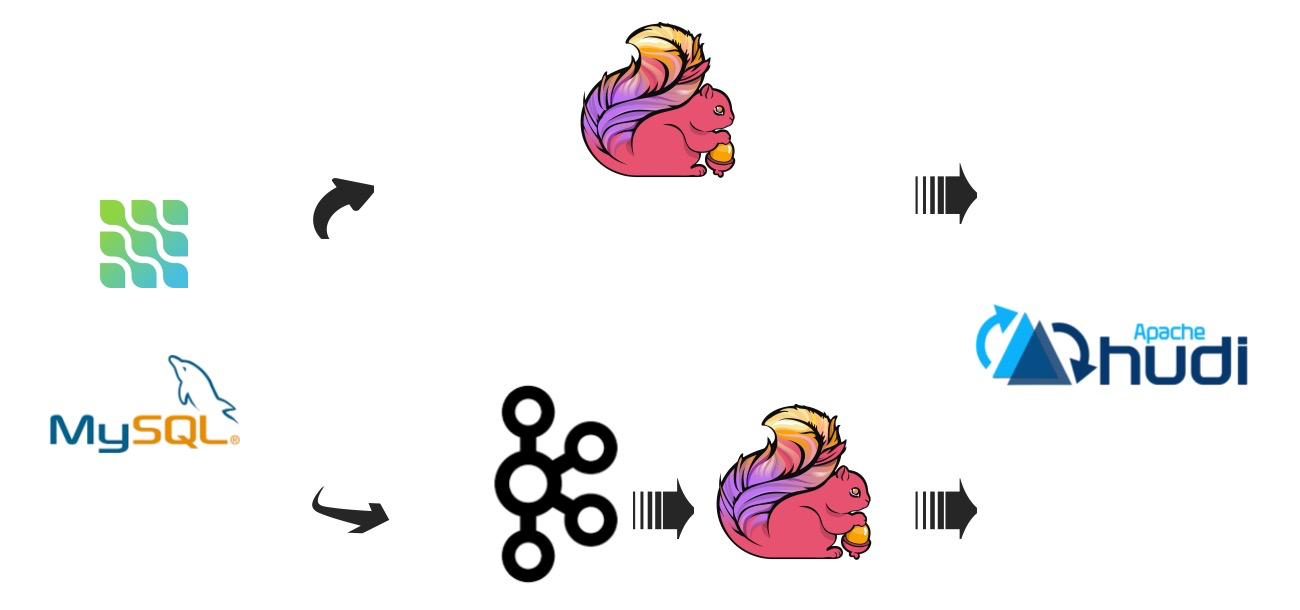
Apache Hudi 的出现,给静态的数据湖装上了可以处理变更的引擎。它本质上是一种数据湖上的存储抽象,支持在HDFS这类分布式文件系统上进行数据的 upsert 和增量消费。这意味着数据湖里的数据不再是只读的,也能被更新了。
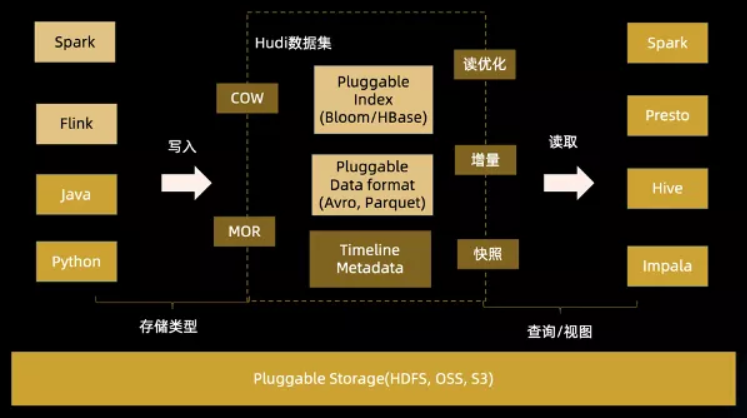
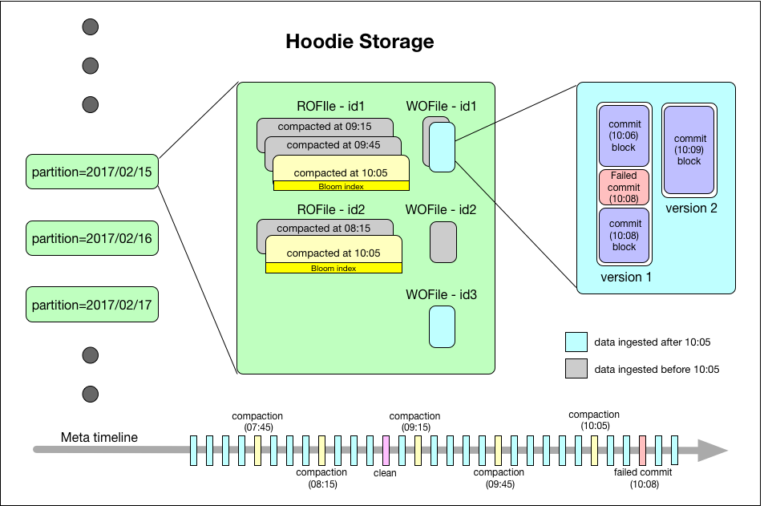
Hudi 的核心是维护了一个时间轴,记录下所有对表的操作。配合索引机制,它能快速定位一条记录所在的文件,从而实现高效的更新和删除。这让数据湖开始具备部分数据仓库的特性,但底层的存储依然是大数据文件。
Flink + Hudi 构建实时湖仓一体
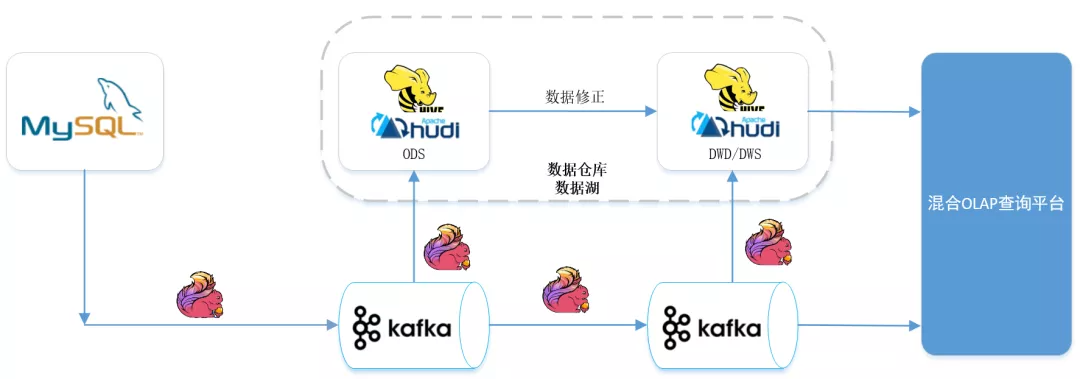
Hudi 从0.7.0版本开始与Flink深度整合,支持Flink SQL和CDC数据接入。这使得我们可以用Flink实时消费Kafka的binlog,直接写入Hudi表,数据的时效性可以达到分钟级,满足业务对实时数仓的需求。

通过这套组合拳,企业在准实时场景下能实现数据同源、同计算引擎、同存储、同计算口径。以前需要维护Lambda架构的批和流两条链路,现在可以用Flink + Hudi一套搞定,大大简化了技术栈和运维成本。
Hudi 的存储结构与索引机制

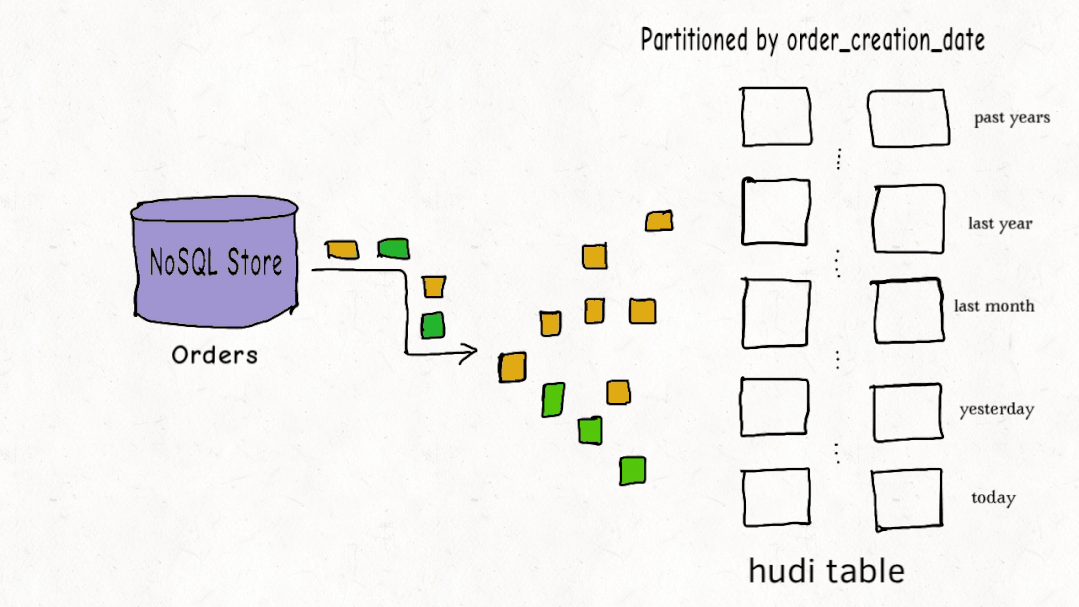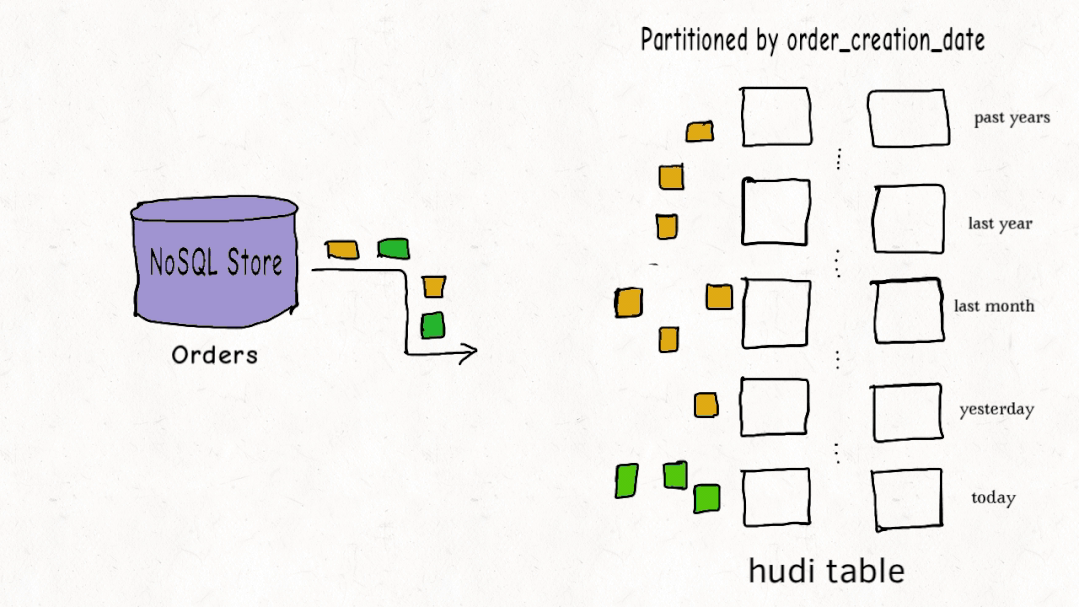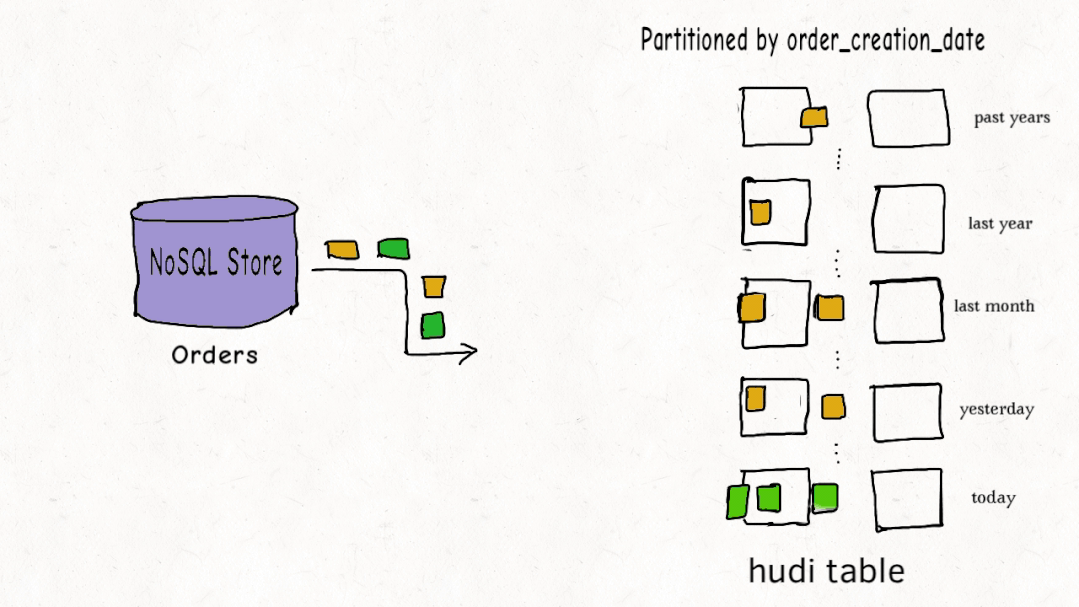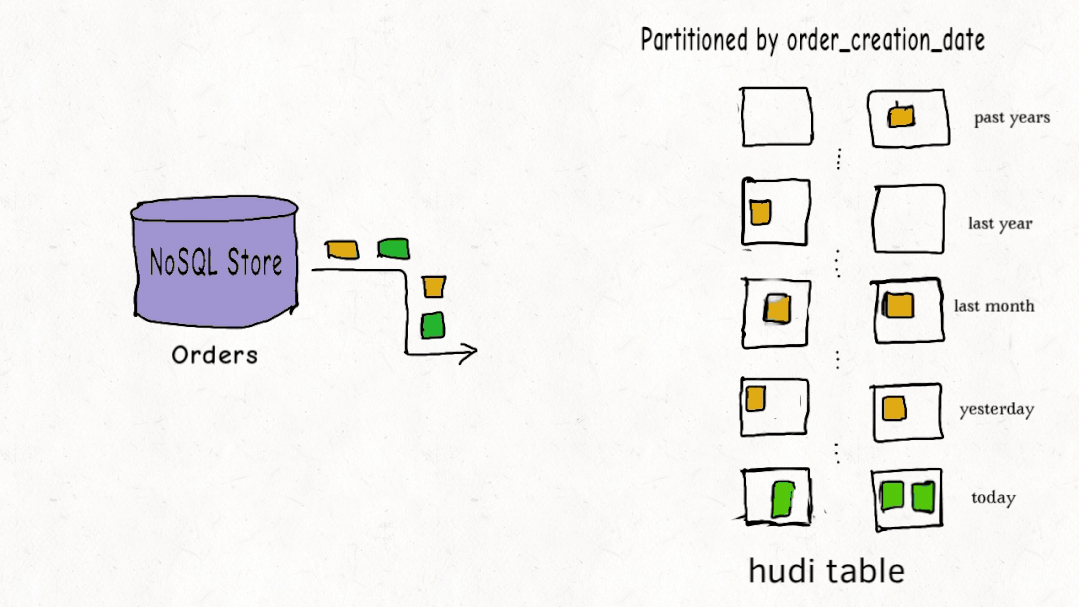
从存储结构看,一个Hudi表在HDFS上分为数据文件和元数据。数据文件按Hive表的分区方式组织,比如按日期分文件夹。元数据目录则记录了表的各项操作和索引信息,用于快速定位数据。
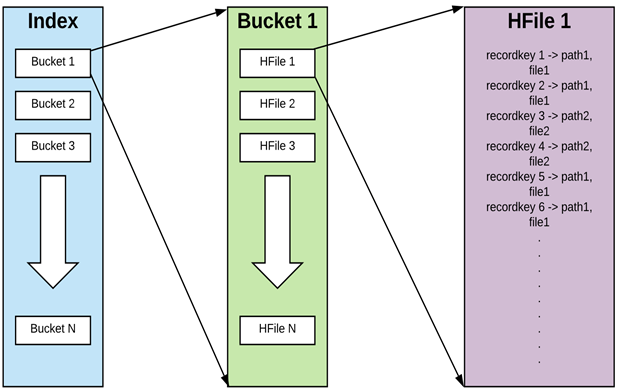
为了实现高效的更新,Hudi引入了索引机制,将记录的主键和分区路径联合作为唯一键。当新数据进来时,索引能快速判断这条记录是应该插入还是更新,并找到它所属的旧文件。对于按时间分区的实时写入场景,BLOOM过滤器索引表现很好,能大幅减少需要比对的文件数量。
不同工作负载下的索引选择
对于像订单事实表这样不断有新数据流入的场景,BLOOM索引加上范围修剪能有效过滤掉大量不相关的旧文件。因为新数据通常落在最新的几个分区里,索引很快就能确定需要更新的文件范围。
而对于像用户画像这种高维度的缓慢变化维表,更新可能随机落在任何分区。此时BLOOM索引的效果就不理想了,因为它可能提示几乎所有文件都需要检查。这种情况下,使用HBase这样的外部索引来做随机查找会更合适,虽然引入了额外组件,但能保证更新性能。

数据湖的未来是湖仓一体
数据湖和数据仓库的争论可以停一停了。未来的趋势是湖仓一体,数据湖作为统一存储层,保留其低成本、多格式的优势,同时通过Hudi这样的技术补上数据管理和事务处理的能力。
企业构建数据架构时,应根据场景选择技术。对于复杂的ETL和数据探索,用数据湖。对于固定的报表和可视化分析,还是跑在数据仓库上更靠谱。两者结合,才是性价比最高的方案。
看到这里,你所在的公司目前是如何平衡数据湖和数据仓库的呢?是用一套架构通吃,还是让它们各司其职?欢迎在评论区分享你的实践经验,也别忘了点赞转发,让更多人看到这篇干货。