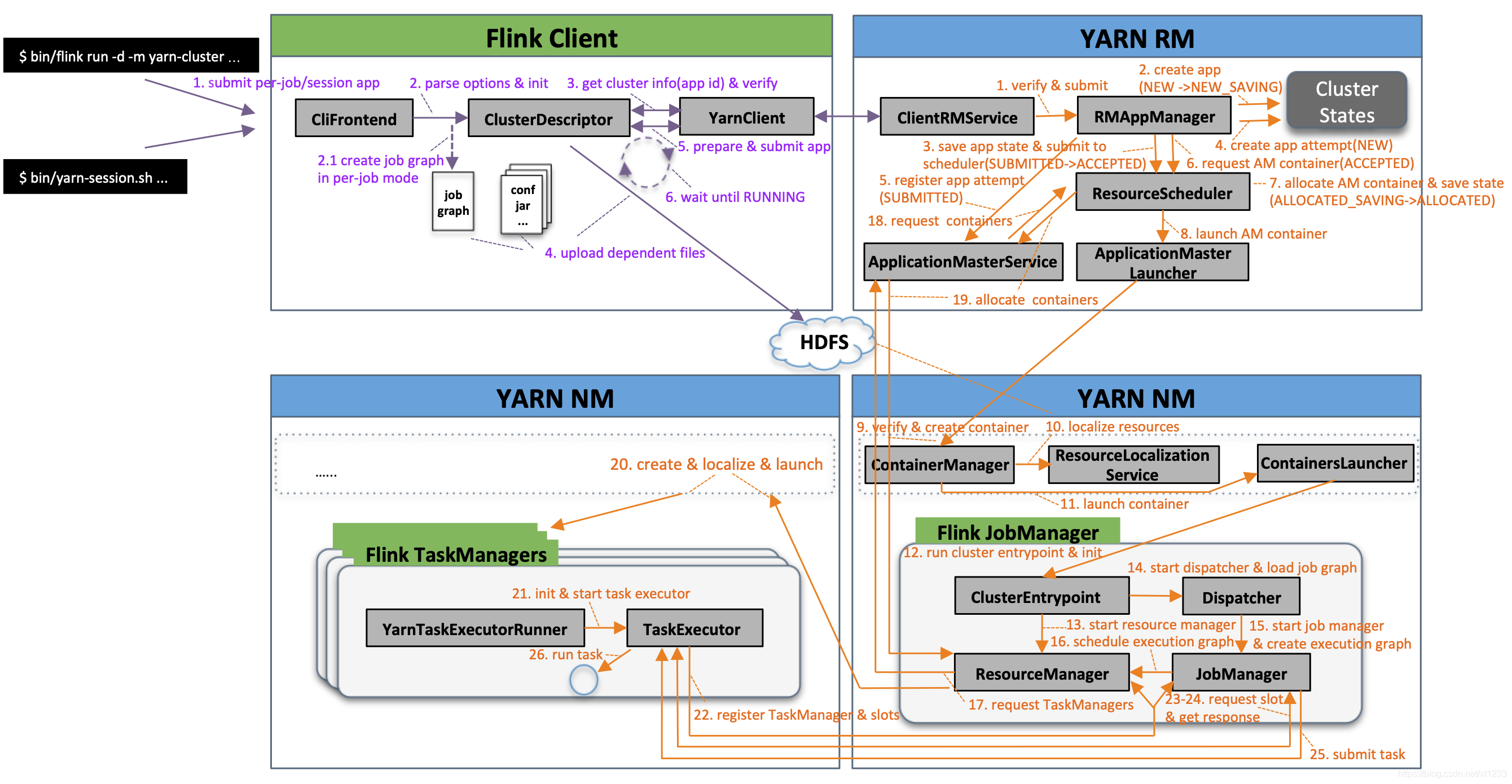
想要在由廉价机器组成的集群上稳定运行批处理程序已经够让人头疼了,而流处理程序的可靠运行更是难上加难,其核心挑战在于如何保证分布式系统中有状态计算的数据一致性。
什么是有状态和无状态计算
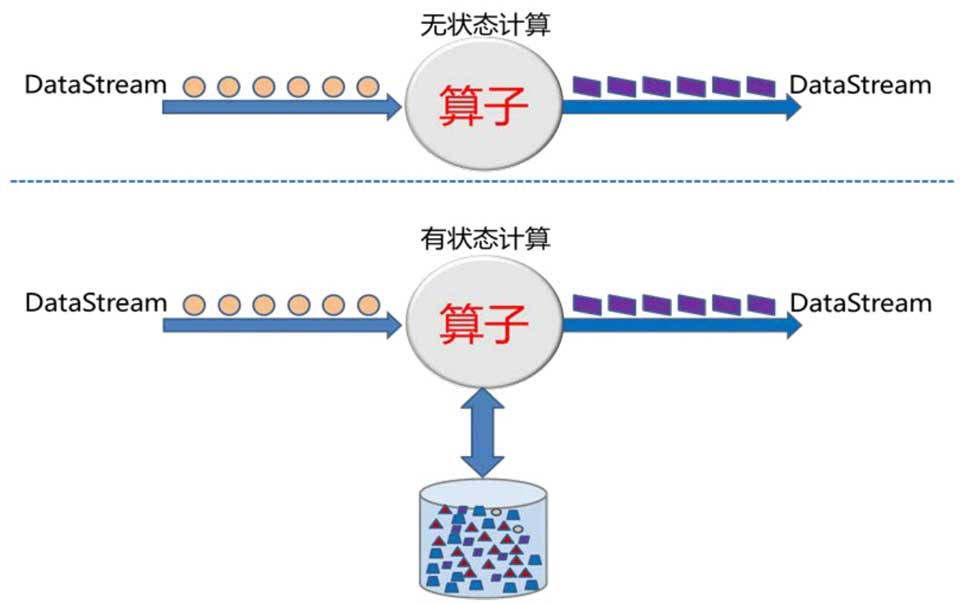
在数据处理中,像过滤掉单个异常值这样的操作,只依赖于当前这条数据本身,不需要记住之前的数据,这就是无状态计算。例如,2026年3月某电商平台的实时点击流中,过滤掉机器人的点击,每条点击独立判断即可。
而有状态计算则必须记住历史数据。比如计算过去一小时内每个商品的累计销量,窗口必须缓存这期间的所有订单事件或中间累计值。在分布式环境中,这些状态分散在多台机器上,一旦某台机器宕机,内存中的这些累计数据就会丢失,导致最终结果出错。
数据一致性语义的三种级别
当系统发生故障恢复后,数据处理结果可能会出现偏差。最宽松的是“at-most-once”,即数据可能会丢,比如故障前窗口内的某些事件再也找不回来了,导致聚合结果偏小。

“at-least-once”保证数据不丢,但可能重复。例如,2026年3月10日上午的实时大屏监控中,某个故障恢复后,同样的点击量被统计了两次,导致指标虚高。而最严格的“exactly-once”则要求故障恢复后的结果与从未发生故障时一模一样,这需要强大的技术支撑,Flink的异步屏障快照正是为此而生。
检查点与屏障的核心概念
理解异步屏障快照前,需要先知道检查点。就像MySQL数据库不会每写一条数据就刷盘,而是先记日志,定期做个标记点,故障后从这个标记点恢复即可。在Flink中,这个标记点就是检查点,它记录了某个时刻所有计算任务的状态。
而“屏障”是Flink为实现检查点而插入到数据流中的特殊标记。它随着正常数据流动,像一条分界线,将数据流切分为“检查点之前的数据”和“检查点之后的数据”。当计算节点接收到所有上游发送来的屏障时,就会触发本节点状态的快照保存。
异步屏障快照的工作机制
同步快照需要暂停整个处理引擎来统一拍照,这在大流量下会严重影响吞吐量。Flink采用异步机制,计算任务在正常处理数据的同时,后台异步地将状态持久化到存储系统,比如HDFS或DynamoDB中,极大地减少了性能损耗。
异步屏障快照能保证exactly-once的核心在于其算法。它要求快照仅包含节点处理完“检查点屏障”之前所有数据后的状态,而不包括仍在传输通道中排队的数据。通过全局唯一的快照ID,引擎可以精准地恢复出整个计算图在那一时刻的完整状态。
Flink中状态的存储与恢复
Flink窗口的状态不仅包含了窗口内累计的业务数据,如商品销量的中间结果,还包含了事件时间和水位线的推进情况。这些元数据对于故障后准确恢复窗口触发时机至关重要,也说明了时间管理增加了流式引擎的复杂度。
当任务失败时,JobManager会触发重启。所有并行实例从持久化存储中读取上一个完整的可用快照,重新初始化各自的状态。这就像游戏存档,读取后从存档点继续玩,保证了处理结果的精确一致性。Flink的状态后端可以配置为RocksDB,实现增量检查点,减少存储压力。
保存点在应用升级中的实践
保存点与检查点机制底层相同,但它是用户手动触发的,主要用于应用平滑升级。比如某公司计划在2026年3月10日晚间将实时风控程序从V1.0升级到V2.0,运维人员可以先对V1.0当前时刻的运行状态做保存点。
用这个保存点去初始化V2.0版本的程序,并让其接替工作。在整个过程中,旧版本仍需继续运行直到新版本确认正常,以便随时回退。这种通过保存点实现的版本状态管理,确保了业务在升级过程中数据不丢不重,实现了真正的服务无缝切换。
你在实际工作中是否遇到过因为流处理程序故障导致数据对不上的情况?当时是怎么排查和解决的?欢迎在评论区分享你的经验,觉得本文有用的话记得点赞收藏!