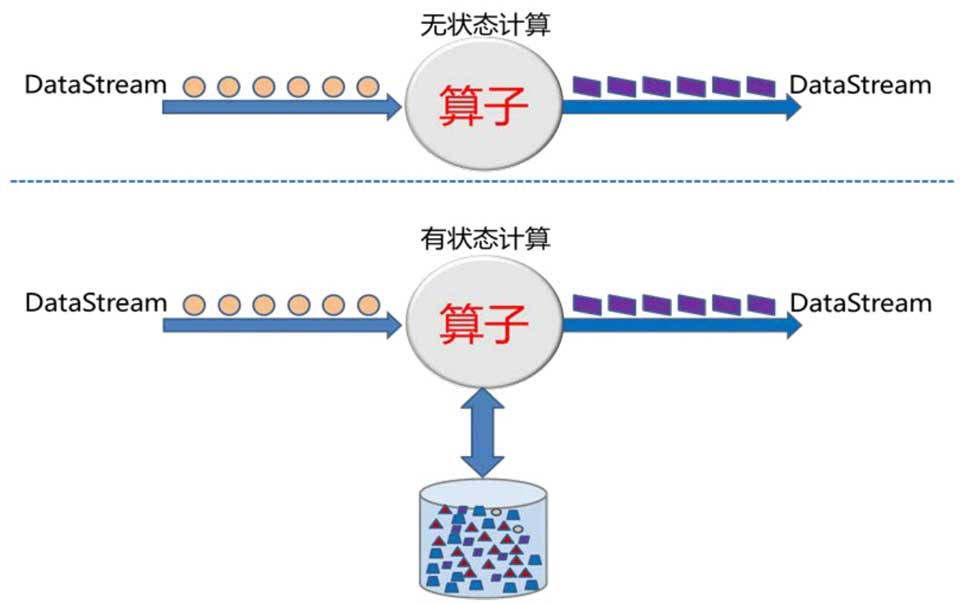
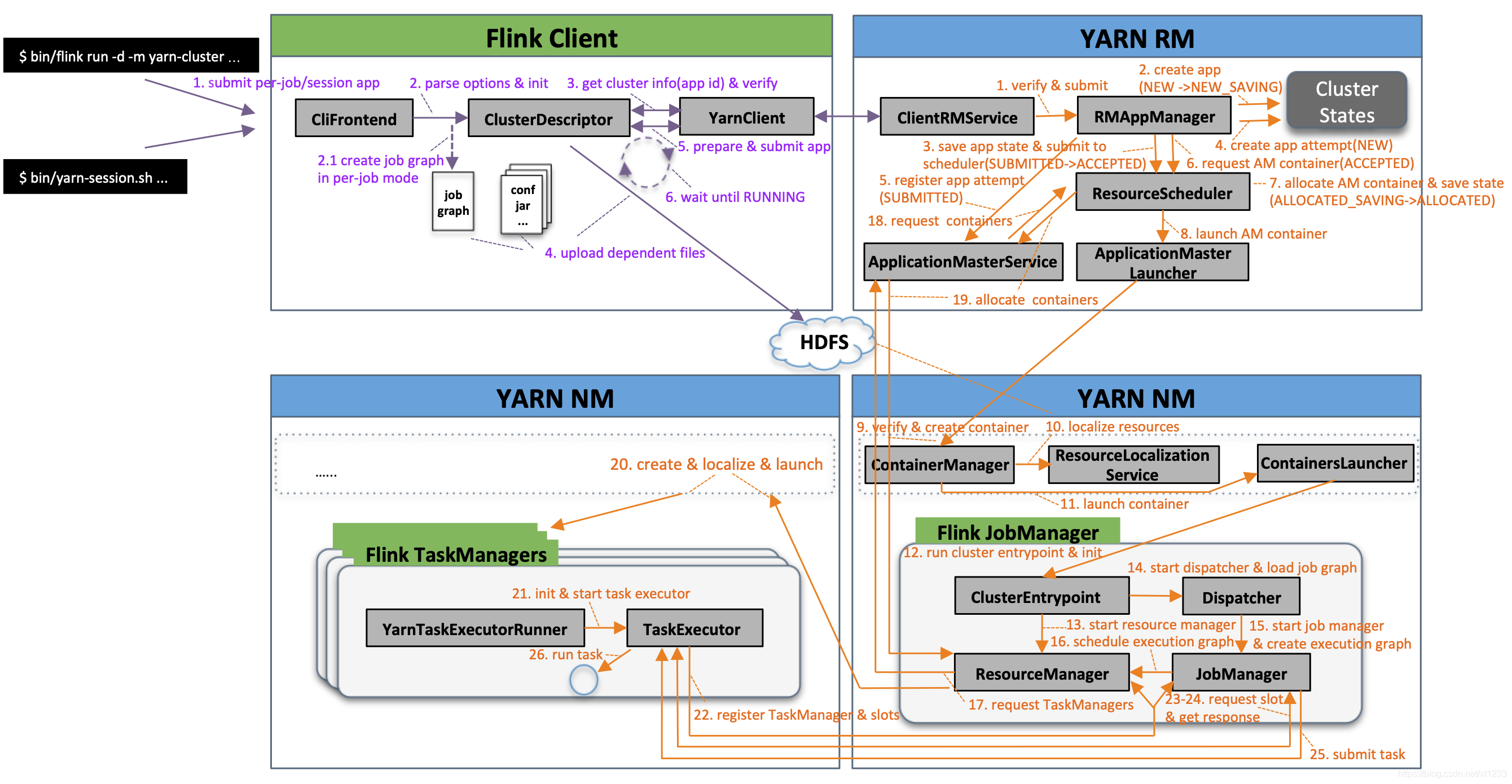
当你用 Flink on YARN 提交一个任务时,背后其实藏着一套非常精密的资源调度流程,尤其是经过 FLIP-6 重构之后,整个启动过程变得更加模块化和清晰。了解这些步骤,能帮你更快定位问题,也能让你对 Flink 和 YARN 的协作有更深刻的理解。
从命令行到集群的第一步
当你在终端敲下 flink run 命令并带上各种参数时,Flink 的客户端就开始干活了。它会首先解析你输入的所有参数项,比如 -m yarn-cluster、-ynm 任务名称等,并根据这些参数初始化运行环境。如果检测到是 per-job 模式,客户端会根据你指定的主类,生成对应的 JobGraph。如果参数里没有 -yq 这种查询资源的指令,就会正式进入提交应用的流程。
这个初始化过程非常关键,它决定了你的任务将以什么身份、什么资源需求去跟 YARN 打交道。所有你配置的队列名、标签、资源大小,都会在这个阶段被封装起来。客户端还会注册一个 hook,用于在部署失败时清理 HDFS 上的临时目录,防止垃圾文件残留。
向YARN RM申请一张入场券
客户端准备好后,会向 YARN 的资源管理器(RM)发送请求,创建一个新的应用。RM 的 ClientRMService 组件会接收这个请求,经过简单校验后,转交给内部的 RMAppManager 来处理。这时候 YARN 会生成一个唯一的应用 ID,并返回给你一个资源上限,告诉你集群最多能给这个应用多少资源。
与此同时,客户端还会顺手获取一份 Node 报告,也就是所有 YARN 节点的状态信息。这里面包含了每个节点的 ID、状态、Rack 信息、HTTP 地址,以及当前的总资源和已使用资源。这些数据虽然不直接参与后续的分配决策,但能让你在提交前就对集群水位有个大致了解。
提交上下文与状态流转
拿到应用 ID 后,客户端开始准备真正的提交内容,也就是 ApplicationSubmissionContext。这里面打包了应用名称、类型、队列、标签,还有一大堆环境变量和资源文件的位置。这个上下文信息会被提交给 YARN RM,然后 RM 内部开始正式管理这个应用的生老病死。
应用的状态会经历多次变化,从 NEW 开始,经过 NEW_SAVING 持久化到状态存储,再到 SUBMITTED。状态存储是个重要机制,它会把应用的元数据存到 Zookeeper 这样的外部系统里,这样即使 RM 发生故障或切换,新上线的 RM 也能把应用恢复回来,不至于让任务人间蒸发。
容器分配与NM的启动交响曲
应用被接受后,RM 开始为 AM 申请资源。这个过程涉及复杂的队列优先级比较,从根队列往下层层筛选,结合集群当前的空闲资源,最终选出合适的节点。一旦 AM 容器分配成功,状态会变为 SCHEDULED,然后触发 NM 的启动流程。
在 NodeManager 端,ContainerManager 会负责拉起 AM 容器。它会先校验 Token 和资源文件,然后创建 Container 实例并存储到本地。接着会启动一个叫 ContainerLaunch 的组件,它的工作是创建工作目录、从 HDFS 下载 Flink 依赖和用户 Jar 包,并把所有文件分散到不同磁盘上,避免 I/O 热点。最后,它会把启动命令写入一个 .sh 脚本,然后执行这个脚本来启动 AM 进程。
AM注册与心跳长连接
AM 进程启动后,会初始化 Flink 自己的资源管理核心,也就是 ResourceManager。它包含两个子组件,一个负责跟 YARN RM 通信,另一个负责管理内部的 Slot 资源。接着 AM 会创建心跳线程,向 YARN RM 的 AMRMClientService 发起注册。
注册成功后,AM 就开始定期发送心跳,默认是 5 秒一次。这个心跳不仅仅是为了保活,更重要的是在心跳中带上资源请求,或者获取 YARN 新分配的资源。如果 AM 超过 10 分钟没发心跳,RM 就会认为它挂了,触发 AM 失败重试流程,保证任务的鲁棒性。
从JobGraph到物理执行
在 per-job 模式下,AM 启动后紧接着会拉起 Dispatcher 和 JobManager。Dispatcher 负责接收作业,而 JobManager 会从工作目录加载用户 Jar 和 JobGraph。然后它会构建 ExecutionGraph,这是 JobGraph 的并行化版本,包含了所有可以并行执行的任务。
当 Slot 资源就绪后,JobManager 会把 Task 调度到对应的 Slot 上。如果 Slot 不够,JobManager 会通过 ResourceManager 向 YARN 申请新的 Container。YARN 分配后,新的 TaskManager 进程会被拉起,它加载 UserCodeClassLoader 并启动 Task 执行。至此,整个 Flink on YARN 的启动流程才算走完,你的数据流也开始真正跑起来了。
如果你在提交任务时遇到过“超时”或“资源分配慢”的问题,你觉得最可能卡在了哪个环节?欢迎在评论区分享你的排查经验,也别忘了点赞收藏,方便以后复盘。