阿里大数据这几年的发展速度确实惊人,每天要处理的数据量已经达到EB级别,支撑着淘宝、天猫、菜鸟等几十个业务线。这种超大规模的业务场景下,传统技术根本无法满足需求,尤其是在双11这样的极端峰值时刻,每秒处理的数据量能达到数亿条。这不仅是技术实力的体现,更是对未来更大数据挑战的提前布局。


计算力与智能化双轮驱动

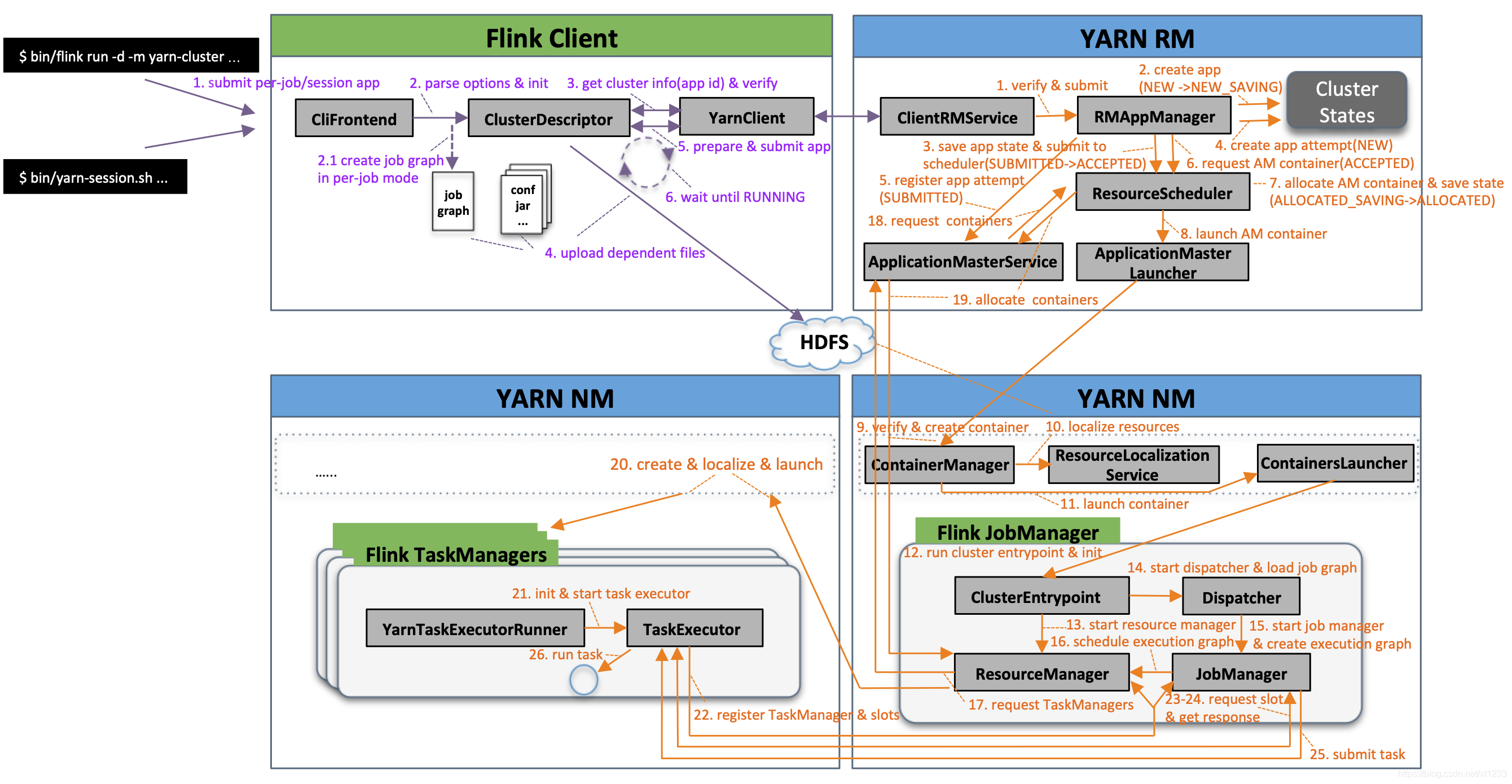
阿里巴巴大数据的发展策略现在非常清晰,就是要进一步提升计算力和智能化水平。计算力方面,通过不断优化底层计算引擎,让同样的硬件资源能处理更多的数据,成本更低效率更高。智能化则是让系统能够自动感知数据特征,动态调整计算策略,减少人工干预。

企业级服务能力的增强也是重中之重,这意味着不仅要满足内部海量业务的需求,还要把成熟的技术沉淀下来,形成标准化的产品和服务。目前阿里内部已经有超过10万个计算任务在稳定运行,覆盖了搜索、推荐、广告、风控等核心业务领域,这套体系正在变得越来越健壮。
Blink开源背后的战略考量

靖人在分享最后宣布的Flink内部版本Blink开源计划,时间点定在2019年1月,这个决定背后有着深远的考虑。阿里巴巴过去两年对Flink进行了大量的深度改造,包括全新的网络流控机制、基于容器的HA方案、增量checkpoint机制等,这些改进让Flink能够在阿里的超大规模场景下稳定运行。
开源这些内部改进的初衷很简单,就是希望让整个Flink生态都能受益。毕竟社区版Flink在阿里这样的规模下直接使用是不现实的,现在把这些经过实战检验的改进贡献出来,可以让所有Flink用户提前享受到这些成果,也能吸引更多开发者参与到Flink的建设中来。

实时BI驱动业务决策
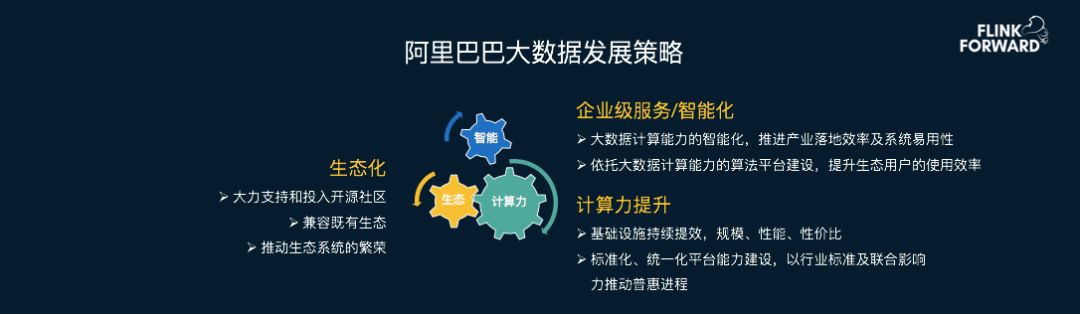
Flink在阿里内部最典型的应用场景就是实时BI,这个需求源于阿里海量的在线交易数据。每天有几亿用户在淘宝天猫上产生行为,运营团队需要实时看到各个维度的统计指标,比如不同类目的成交额、各个地区的购买力变化、热门商品的实时排行等。

双11实时GMV大屏已经连续两年由Flink支撑,2017年双11当天的实时成交额峰值达到每秒32.5万笔。这个看似简单的数字背后,实际上是上万个Flink计算任务在平稳运行,它们要保证数据不重不漏、延迟在秒级以内、计算结果绝对准确,任何一个环节出问题都会影响大屏显示。
在线学习实现实时智能
在线机器学习是Flink的另一个杀手级应用场景。传统的离线机器学习方式需要T+1分析用户历史行为,训练出的模型第二天上线时可能已经过时了。比如用户昨晚刚搜过羽绒服,今天早上模型应该知道他对保暖商品有兴趣,但离线模型可能还停留在昨天的状态。
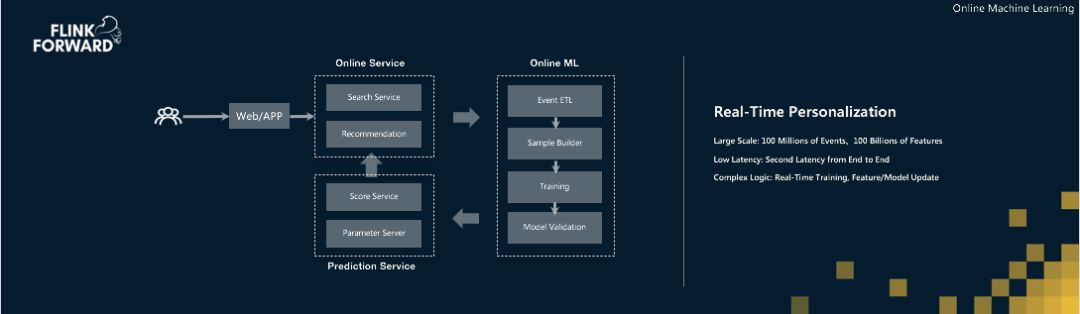
在线学习系统通过Flink实时收集用户行为数据,进行流式特征计算,模型增量更新秒级同步回在线系统。在阿里的业务规模下,这套流程要处理数亿用户的实时行为数据,计算复杂度极高,但Flink能让整个闭环在几秒内完成。搜索推荐算法平台现在已经是流批统一基于Flink运行,特征计算和模型训练的效率大幅提升。
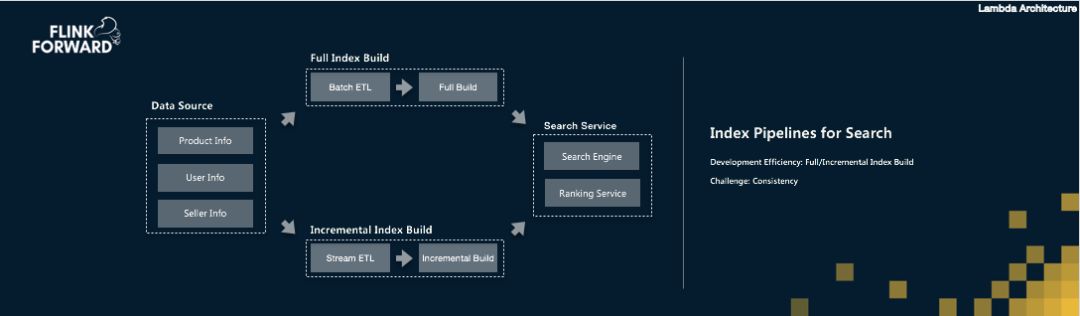
批流融合架构优势明显
阿里很多业务场景同时需要实时流处理和离线批处理,比如商品搜索索引构建。白天要把商品更新信息实时同步到搜索引擎,让用户能搜到最新商品;晚上则要对全量商品数据做批处理,构建完整的索引文件。传统做法需要开发两套代码、部署两套集群,成本和维护难度都很高。
Flink基于流处理实现批流融合的架构,比Spark基于批做流的方式更自然。阿里在这个方向上做了大量工作,包括全新的DataStream API设计、灵活的调度和网络插件化机制。在TPC-DS标准测试中,Blink在1T、10T和30T数据规模下全面超越Spark,数据量越大优势越明显,充分验证了这套架构的先进性。

Flink未来演进新方向
蒋晓伟在分享最后给出了Flink未来的几个发展方向,除了继续深化批流融合,还应该在机器学习和图计算生态上加大投入。现在AI浪潮正热,Flink如果能更好地支持在线学习、实时特征计算,就能在这个领域占据重要位置。
更长远的目标是让Flink同时向两个方向延伸:往离线方向做到真正的批流融合,往实时在线方向支持Event-Driven架构。未来的应用可能不再是简单的APP+数据库模式,而是像城市大脑这样的复杂系统,所有组件都运行在云上,Flink作为核心实时计算引擎,处理各种结构化和非结构化数据,支撑起整个智能体系。
看完阿里在大数据领域的这些探索,你觉得Flink未来最有可能在哪个行业率先实现大规模落地?欢迎在评论区分享你的看法,如果觉得文章对你有帮助,记得点赞转发让更多人看到。