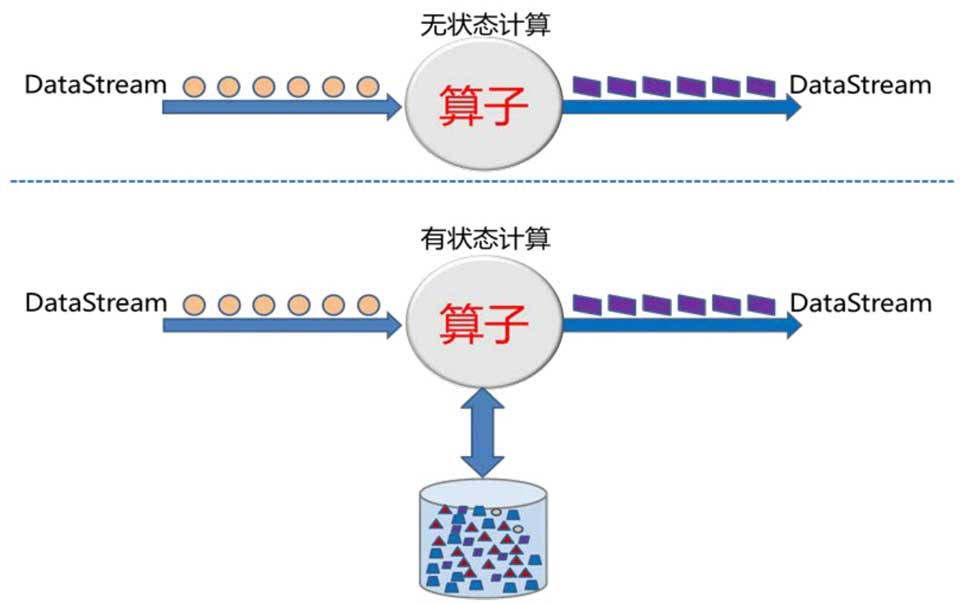
流式计算早已不是简单的数据转换,真正的难题在于如何让实时计算结果被外部系统高效、一致地使用,而这恰恰是当前大多数流式计算引擎忽视的痛点。
持续计算不仅仅是流处理
传统的流式计算引擎比如Storm和Spark Streaming,主要关注点集中在数据本身。它们擅长对每条数据执行map操作,或者对窗口内的数据进行聚合统计。但在真实的企业应用中,这仅仅是冰山一角。
一个完整的实时数据处理系统,需要处理数据接入、流式计算、结果存储、数据服务等多个环节。流式计算引擎只是其中的计算核心,它需要与上下游的各种系统进行复杂的交互,才能构建出真正可用的实时应用。
实时数据服务与计算的融合
在很多场景下,流式计算的结果需要被其他应用实时查询。比如电商大促时的实时销量统计,需要更新Redis或MySQL,然后通过Web界面展示给运营人员。这里就出现了一个技术难题:当流式计算正在更新数据时,用户的查询请求该如何处理?
这要求我们不能只考虑计算本身,而要把数据服务和计算当作一个整体来设计。需要处理读写并发、数据一致性问题,确保用户在任何时刻查询到的数据都是准确和完整的,这就要求系统具备事务性的数据更新能力。
跨存储系统的数据迁移挑战
另一个常见场景是数据迁移,比如将Kafka中的日志数据清洗后写入Elasticsearch或HDFS。这个过程中最大的风险是数据丢失或重复计算。流式计算引擎如何保证与外部存储系统的交互是精确一次的?
这不仅仅是计算引擎能保证自身处理一次就够了,还需要与外部存储系统协调。比如在写入失败时需要回滚,在重启时需要从正确的位置继续消费。这些复杂性如果都推给开发人员手动处理,不仅效率低,而且极易出错。
实时与批量计算结果的一致性
很多企业同时拥有实时计算和离线计算两套任务,用于支撑不同的业务场景。比如实时大屏看今日销量,离线报表看历史趋势。但经常会出现实时指标和离线报表对不上号的情况,导致数据团队反复被质疑。
根本原因在于流式计算和批处理对同一份数据的计算逻辑很难完全一致。流式计算为了追求低延迟,往往采用近似算法或不同的窗口触发机制。而用户期望的是无论实时还是离线,相同口径的数据结果应该是完全一致的。
Spark Structured Streaming的解题思路
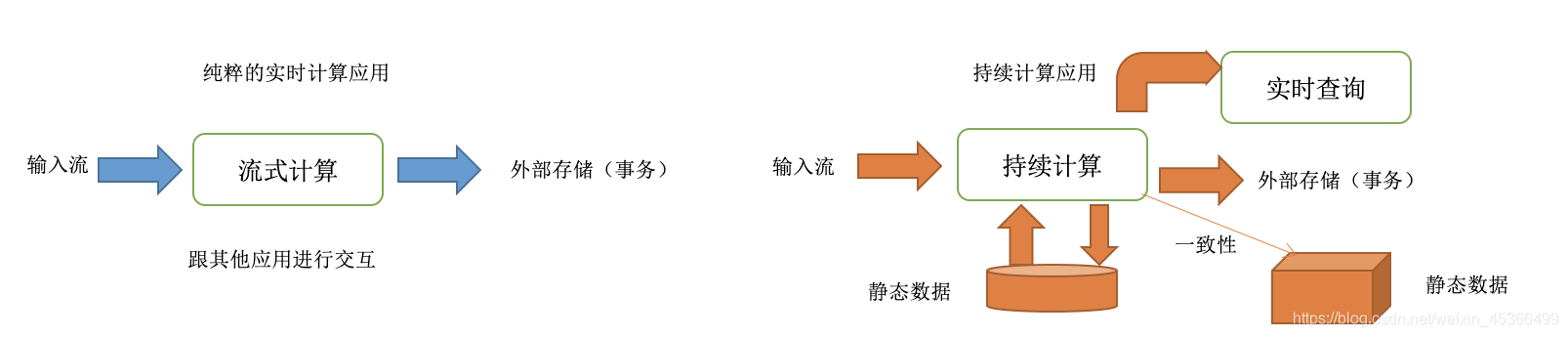
针对上述痛点,Spark提出了Structured Streaming,它的核心思想是将数据流抽象为一张无限追加的表。开发者可以用处理静态表的方式编写流式查询,Spark再将其转换为增量的、持续的执行计划。
这种模型带来的最大好处是,流式计算的结果在任何时刻都与用批处理方式处理相同数据的结果完全一致。它从根本上解决了实时与离线结果对不齐的问题,开发者不再需要维护两套逻辑。
事务性写入与端到端一致性
Structured Streaming在设计之初就考虑了与存储系统的整合。它通过内置的API支持对Kafka、MySQL、Redis等外部存储进行事务性的批量更新,保证了数据被处理一次且仅一次。
这意味着当流式作业失败重启时,Spark能自动协调消费偏移量和外部存储的写入状态,确保不会产生重复数据或丢失数据。开发者无需再手动编写复杂的恢复逻辑,可以更专注于核心的业务转换。
构建完整的持续计算应用
持续计算应用的理念是,用一套统一的API和引擎,覆盖数据实时处理的全部环节。从数据接入、流式计算,到结果的数据服务,甚至包括与离线批处理作业的交互和机器学习模型的实时预测。
这种整合极大地降低了系统的复杂度。开发者不再需要拼接多个独立的系统,处理它们之间的数据一致性问题。Spark希望通过DataFrame和Dataset这些高阶API,让构建一个健壮、一致的实时应用,变得像开发批处理程序一样简单。
你在实际工作中,是否也遇到过实时计算与外部存储交互时令人头疼的数据一致性问题?欢迎在评论区分享你的经历和解决方案,点赞和分享本文,让更多开发者少踩坑。