
关于这个自注意力机制,咱一点点来聊一下。,它可是个在神经网络架构里超厉害的家伙,是在2017年的时候,被他们在《 Is All You Need》这篇论文当中头一回提出来的,可以说是一下子就改变了自然语言处理领域,还慢慢把传统的RNN和CNN架构都给替代
特点梳理
独特优势:它可完全是靠着注意力机制在这搞事情咧,把传统的循环和卷积结构都给弄一边去。并且它并行计算的能力超强不像那个RNN只能按顺序一点点算。还有厉害的一点就是它对长距离依赖能够给很好地捕捉,不管是多离谱的距离依赖关系,它都能通过这个所谓的自注意力机制很好地抓到。而且它设计还是模块化的,用编码器 – 解码器的结构,清晰得不得了,爱怎么扩展就怎么扩展。
### 核心组件分析
输入嵌入层:咱们先说这编码器,这里面头一个组成部分就是输入嵌入层。这输入嵌入层,就是能把输入进来的token转变为那种稠密向量表示,一般来说维度要么是512,要么比这还大的数。这里面还有那种能学习的参数矩阵
位置编码:再说到位置编码,它可关键了。为啥,咱这一开始还缺位置信息, 靠它用正弦和余弦函数搞了个固定模式来解决,就是PE(pos,2i) sin(pos/10000(2i/))PE(pos,2i1) cos(pos/10000(2i/)),跟那输入嵌入是相加的关系,可不是拼接
编码器层堆叠:再来就是编码器层堆叠。一般得有6层或者比6层还多,像那原始论文就是用的6层。在每一层咧,都有两个子层。一个是多头自注意力机制,另一个是前馈神经网络。并且每个子层还有啥残差连接和层归一化。
机制计算解析
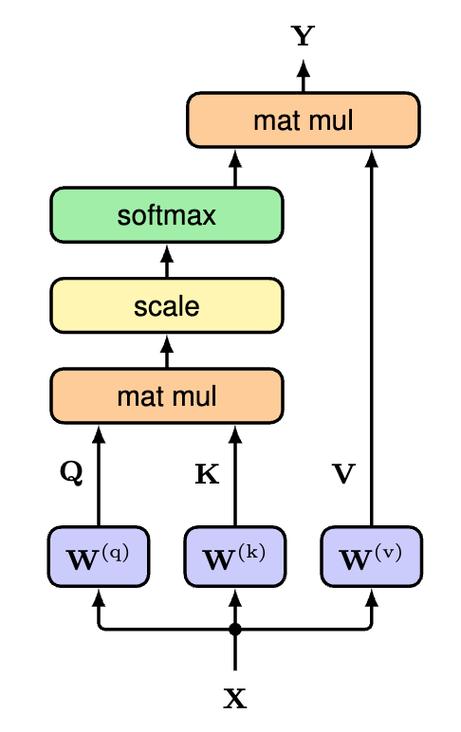
而关键的自注意力机制,它在计算的时候,是这么整滴: (Q,K,V) = (QKⁱ/dₖ)V ,这里面Q就是Query 。咱们要知道Query 、Key还有Value,它们都跟原本输入做线型变换有很大关联,但不同类型会有些许区别。这里有必要说一个缩放因子,也就是计算当中的那个dₖ。它可以起到避免点积结果过大,以至于在通过那个函数的时候梯度太小的作用。
问答互动情况
我明白肯定会有不少好奇鬼有些问题,下面咱来随便看看:
问:的核心是什么?
答:那核心必然肯定就是自注意力机制。靠着它能够高效去捕捉信息当中的依赖关系。它不管是在自然语言处理还是像图像、语音这些其他方面,统统都大有用武之地。
问:输入嵌入里维度有啥讲究不?
答:这里维度常见的就是512,不过也可能存在比这更大的数字。维度大小有时候会对模型处理信息的能力有作用,但合适才是最好的不是越大越好。
我觉得,这个自注意力机制就跟宝藏一样,它让我们搞懂了很多以前在信息处理的时候不清楚的地方,以后也能够有更好的应用和改进咧。







