
那咱们来唠一唠这 深度残差网络,它可是在深度学习发展的大环境里出现得很及时的那么个东西目前深度学习发展那叫一个快速深度神经网络在不少领域那都是取得了相当显著的成功!不过,深度神经网络在训练的时候就面临着例如梯度消失还有模型退化之类的问题咧,这些问题极大地限制了网络的深度还有性能
这时候, 就闪亮登场了它就是为了解决刚说的那些问题给提出来的。那它的模型原理是啥?它是通过引入“残差块”来解决深度神经网络里的梯度消失还有模型退化问题。这个残差块是由一个“跳跃连接”以及一个或者多个非线性层构成。好处可太大,能让梯度直接从后面的层反向传播到前面的层这样就能够更好地训练深度神经网络
接下来讲讲它这结构方面 能构造出特别深的网络结构。正因为它有这样独特的设计,所以在好多任务当中都能有相当优异的表现
从训练的角度来看 一般使用反向传播算法和像随机梯度下降这样的优化算法进行训练。在整个训练期间,要计算损失函数关于权重的梯度,然后利用优化算法来更新权重,目的就是把损失函数给最小化。除此之外为了加快训练的进程并且提高模型的泛化能力,还能运用像正则化技术、集成学习手段
咱们接下了再拆解着细说。比如说这里面很重要的“残差块”。
1. 残差块的结构是基础中的基础它包含的跳跃连接设计得妙极了。这个跳跃连接就像个捷径,让梯度传递不受阻碍,不会因为网络过深就出现梯度消失这种事。
2. 非线性层在残差块里头也起到关键作用。非线性层能够对输入的数据进行复杂的变换,这样让网络可以学习到更高级、更复杂的特征。
3. 不同类型的残差块还有所区别。有些简单的,层数少一些;有些复杂的,层数就多些。但不管哪种,都是围绕解决问题而设计的。
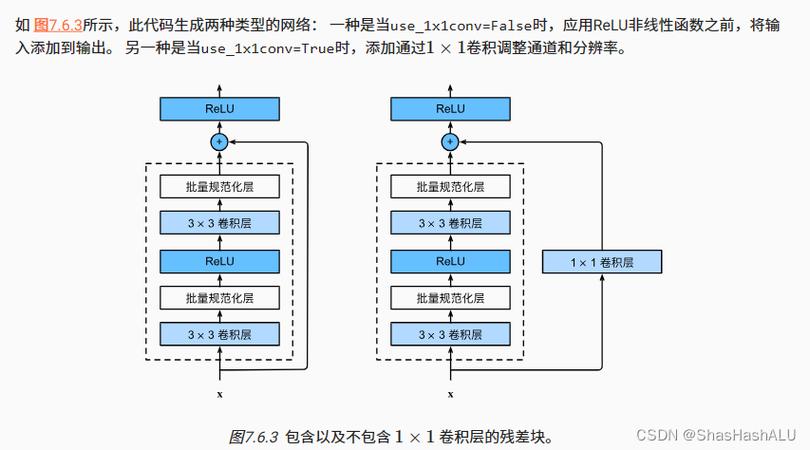
这里和一些传统网络对比下。普通的深度神经网络因为没有跳跃连接,在反向传播的时候梯度经过好多层衰减,就越来越小,导致都很难训练。而 就通过残差块解决了这个问题
现在好多朋友可能有这些问题
问:残差块一般有多少层适宜?
答:这个嘛没有固定值。具体得根据任务的复杂程度确定。任务复杂,层数可以适量增加;要是简单点,那也不用太多层。
问:训练时候对数据量有啥要求
答:数据量当然最好还是多点,毕竟越复杂的网络就越需要大量数据来训练。但也不是说少量数据就不能,只是可能效果没那么好。
我个人觉得, 深度残差网络它的设计真的很棒!它巧妙的解决了深度学习在训练过程中的大麻烦,为后续深度神经网络的发展铺了很好的路就等着未来更多的优秀应用诞生。







