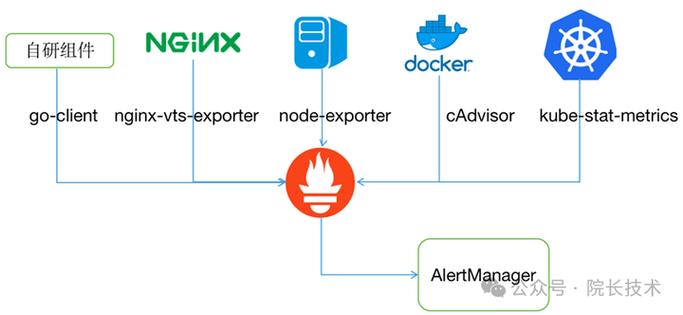
对于运维和开发人员来说,应用性能监控(APM)早已不是选择题,而是保障系统稳定性的必答题。在众多开源方案中,凭借其无侵入的探针能力和强大的分布式追踪表现,成为了微服务架构下排查性能问题的利器。今天,我就结合在生产环境中的实战经验,和大家聊聊如何利用快速揪出拖垮系统的“罪魁祸首”。
如何部署探针不丢数据
很多初次接触的朋友,往往卡在探针部署这一步。探针的部署质量直接决定了我们能看到的数据是否完整。关键点在于解决网络连通性和高并发下的数据积压。建议使用官方推荐的agent方式挂载到Java应用上,并确保.指向正确的OAP 地址。对于核心业务,可以将agent.参数设置为负数,关闭采样率限制,确保全量数据采集。同时,不要忽视agent.的配置,过滤掉静态资源的无效请求,能有效减轻后端存储压力。
告警规则怎么设才有用

告警不是设得越多越好,关键在于精准。我见过很多团队直接把默认规则拿来用,结果要么是告警风暴把人“炸”得麻木,要么是漏掉了真正的隐患。设定规则时,要结合业务的“黄金指标”来思考。比如,除了关注响应时间(RT)和吞吐量(TPS),更要为核心交易链路设置基于“错误率”的滑动窗口告警。利用的alarm模块,我们可以自定义规则,将慢SQL阈值根据业务场景拆分,避免用一套标准卡死所有接口。更重要的是,务必配置好,让告警直达飞书或钉钉,并带上具体的,这样开发人员才能第一时间拿到破案线索。
微服务性能瓶颈如何定位
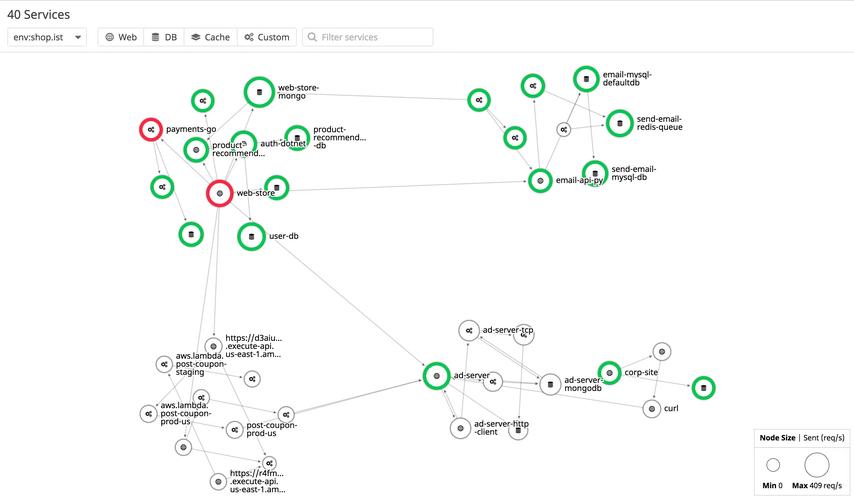
当线上出现接口缓慢时,不要凭直觉猜。在的拓扑图中,可以一眼看出服务间的调用链耗时分布。如果发现某个服务在整体链路中颜色“变红”,就说明它成为了瓶颈。接着,深入该服务的“端点”列表,找出耗时最高的几个接口。此时,利用“追踪”功能查看具体的调用链,重点观察“Span”中是否出现了超过的数据库操作或外部API调用。实战中,我经常发现所谓的“慢服务”,实际上是因为底层MySQL的锁等待或Redis的频繁序列化导致的。通过的数据库语句采集功能,可以精准定位到是哪一行SQL出了问题。
你现在的生产环境中,最让你头疼的性能问题是因为“慢SQL”还是“代码逻辑”造成的?欢迎在评论区分享你的踩坑经历。