在云原生和微服务架构普及的今天,监控早已不是“装个软件看CPU”那么简单。我见过太多团队在引入时,初期用得顺手,数据量一上来就陷入“标签爆炸”、“告警疲劳”、“查询超时”的泥潭。基于多年的实战踩坑经验,我总结了这套真正能落地的最佳实践,希望能帮你搭建一套稳定、高效、低成本的监控体系。
标签设计如何避免爆炸
标签是的精髓,但也是最容易失控的地方。很多新手会把请求ID、用户ID这类高基数数据直接设为标签,这会导致指标数量呈指数级增长,直接拖垮TSDB性能。最佳实践是严格控制标签的基数,确保每个指标的标签组合值在可控范围内。对于需要细粒度追踪的数据,应通过日志或分布式链路追踪系统处理,而不是强行塞入指标中。
告警规则怎样减少误报
告警不是越多越好,无效告警会让人麻木,最终错过真正故障。我在设计告警时,坚持“三个凡是”:凡是能用趋势预测的,不用瞬时阈值;凡是能用多条件组合的,不用单一指标;凡是能加入持续时间窗口的,不加瞬间判断。比如对于内存告警,不要看到超过90%就报警,可以结合“持续5分钟”加上“增长率”来判定,这样能大幅过滤掉业务高峰期的瞬间波动。
长期存储选什么方案
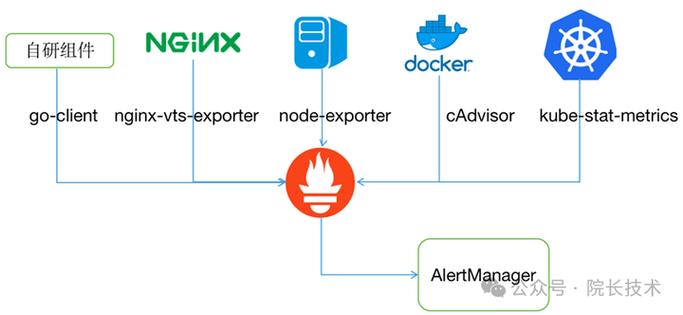
本地存储虽然方便,但受限于单机容量和数据保留时间。当你有超过15天的数据查询需求,或者需要做全局聚合查询时,就必须考虑远端存储方案。我实测过和,前者生态完善但架构较重,后者性能强悍且资源占用低。如果你的团队追求运维简单,是更省心的选择,它能无缝兼容协议,查询速度比原生快数倍。
资源与性能如何平衡
很多人在配置时,要么给太多资源造成浪费,要么给太少导致OOM。关键在于做好容量规划:每个采集目标大约消耗2-3MB内存,每增加100万个活跃时间序列,建议预留8-10GB内存。此外,一定要启用——.tsdb.min-block-来缩短数据落盘时间,避免因内存积压导致进程崩溃。
看完这些经验,你在使用时遇到过最棘手的“坑”是什么?欢迎在评论区分享你的血泪史,如果这篇文章帮到了你,别忘了点个赞支持一下!