网络数据抓取听起来像黑客技术,但它其实是科研人员和市场分析师手里的一把利器,用对了地方能帮你从海量互联网信息中快速挖出真金白银。今天就来聊聊这门技术的门道,让你知道它怎么用、有什么用、又要注意什么。
抓取技术到底是什么
网络数据抓取简单说就是用自动化程序代替人工去浏览网页并收集信息的过程。传统的复制粘贴方式面对几百个网页还能应付,但要收集上万个网站的数据,就必须依靠专门的爬虫程序来完成。
这项技术综合运用了多种计算机手段,包括能够自动访问网页的爬虫机器人、对抓取内容进行智能分词的系统以及管理抓取任务的任务调度器。像搜索引擎公司就是用类似的技术来构建自己的数据库。
抓取数据能用在哪些地方
做学术研究的人经常面临数据不足的困境,网络抓取技术正好解决了这个痛点。比如研究公共政策的学者,需要收集近十年各大媒体关于某一政策的报道,人工翻阅报纸几乎不可能完成。
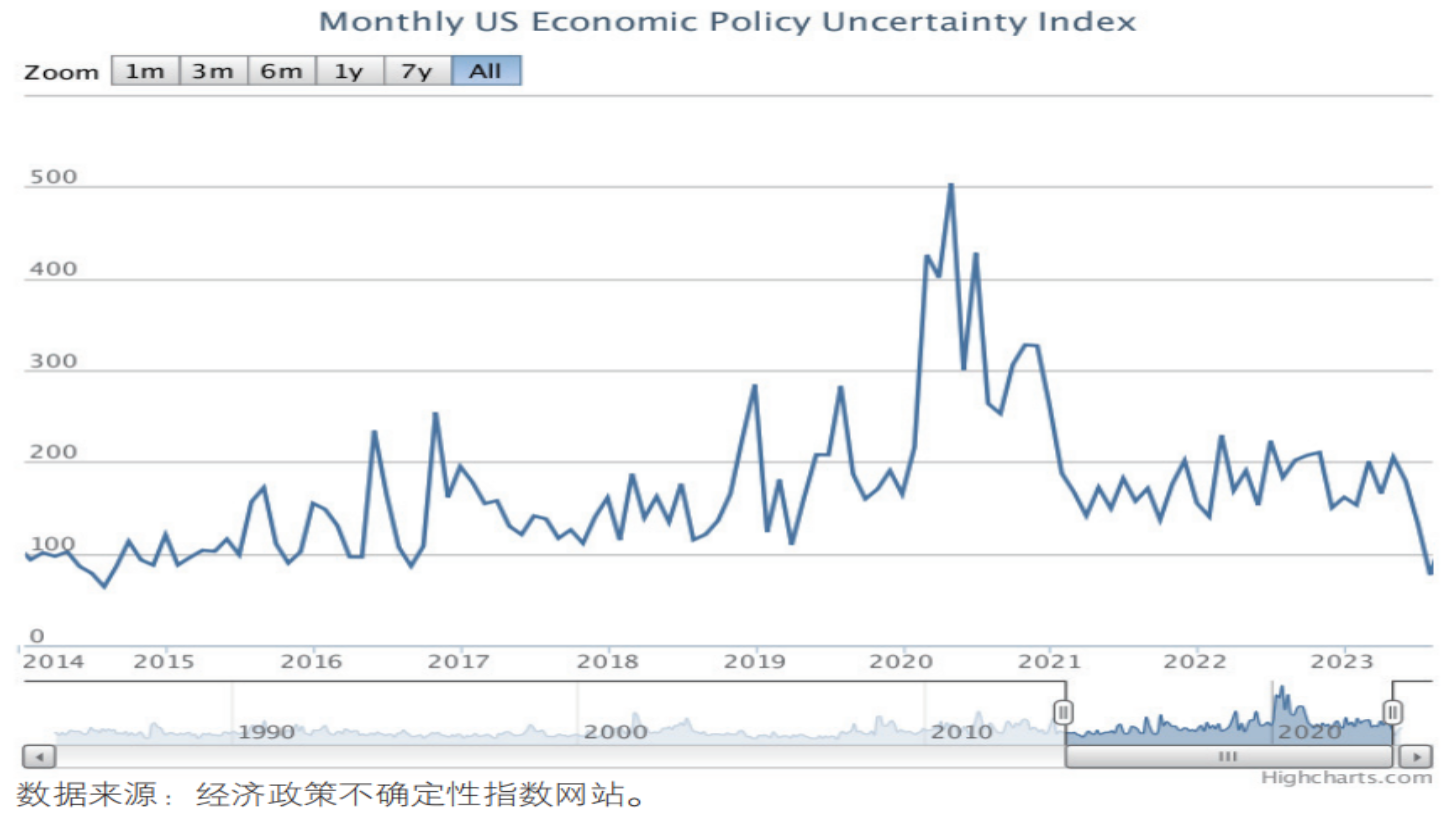
市场调研机构利用这项技术可以实时监控竞争对手的价格变动。2025年某电商研究机构就通过抓取全网家电价格,发现某品牌在双十一前悄悄提价再打折的现象,为消费者提供了真实的价格参考。
抓取流程第一步先定目标
开始抓取数据前必须先明确你要什么信息,这直接决定了后续的技术方案。比如你要分析旅游评论,那就得确定是抓取携程还是去哪儿的用户评价,两个网站的页面结构完全不同。
2026年初就有个研究团队想做民宿价格分析,他们确定了目标网站后,发现不同地区的民宿信息展示方式存在差异,这让他们在后期代码编写时需要考虑更多兼容性问题。
代码编写和测试很关键
分析完目标网站的代码结构后,就要开始编写抓取程序了。有经验的开发者会在这一步尽量找出多个网站的共性,写出一套能够适应多种页面格式的通用抓取代码。
抓取环境测试这个环节绝不能跳过。2025年某数据公司因为跳过测试直接上线,结果程序在抓取过程中触发了目标网站的反爬机制,导致公司IP被永久封禁,整个项目延误了一个月。
数据存储和处理有讲究
抓取下来的原始数据就像刚从菜市场买回来的菜,需要清洗和整理才能使用。一般会把文本内容过滤掉广告和无关信息后,存储到Excel或者CSV文件中,方便后续分析。
当数据量达到百万级以上,就要考虑用MySQL这样的关系型数据库来管理。如果是海量数据,比如每日新增几个G的日志,那就得用Hadoop这样的分布式框架,像阿里巴巴就是这样处理双十一的实时数据。
法律红线不能触碰
2017年实施的网络安全法明确规定了非法获取数据的界限,这几年已经有多起数据抓取引发的法律纠纷。2024年某大数据公司因为未经授权抓取求职网站用户信息,被法院判决赔偿并承担刑事责任。
抓取个人信息必须取得用户同意,这是基本底线。即使是公开的网络数据,也要看网站的robots协议是否允许抓取,像京东和淘宝就明确禁止未经授权的商业数据抓取行为。
看完这篇文章,你觉得在什么情况下使用网络数据抓取技术最容易触碰法律红线?欢迎在评论区分享你的看法,点个赞让更多朋友了解这门技术的正确打开方式。