现在的代码大模型真的会写代码吗?当它们在HumanEval上拿到90%的通过率时,也许只是在背诵题库答案。一个残酷的现实正在浮现:我们引以为傲的评测基准,正变成模型靠死记硬背就能拿高分的“开卷考试”。
数据污染让评测变味
很多主流代码基准集已经存在多年,它们的题目和答案早就在互联网上广泛传播。大模型训练时会把海量代码“吃”进去,其中很可能就包含了这些考题。这就好比赛前给学生发了标准答案,考出来的高分根本不能代表真实水平。

研究发现,一些模型在经典基准上的表现突飞猛进,但在新题上却原形毕露。这种“记忆力”而非“推理力”的提升,让评测结果失去了参考价值。行业急需一种不会被污染的动态评测方式。
测试用例太少导致高分幻觉
传统基准通常只为每个问题准备几个测试用例,这远远不够。模型生成的代码可能刚好蒙混过关,但只要换一个输入就会崩溃。这种“正确的幻觉”让开发者误以为模型很强,实际使用中却频频翻车。
一个典型的例子是,某个模型在评测中得了90分,但在真实项目中几乎无法使用。原因很简单:评测只检查了几种情况,而真实世界的边缘场景成百上千。测试不严谨,高分就变成了虚假广告。
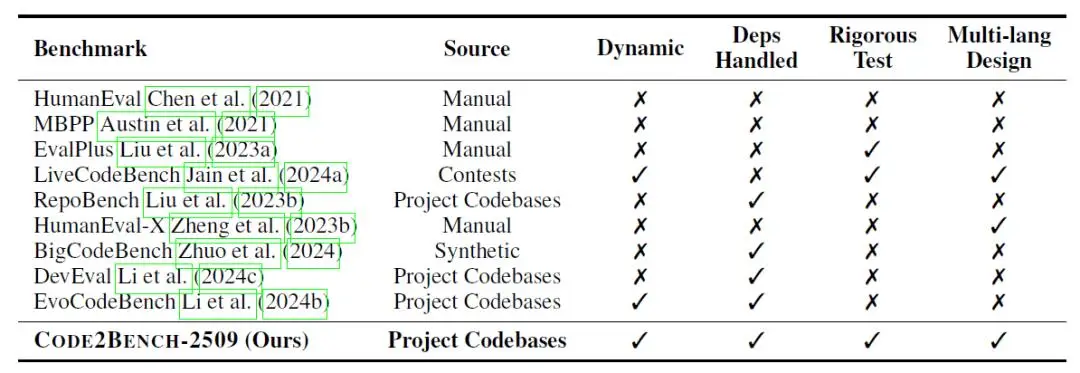
双扩展框架打破静态题库
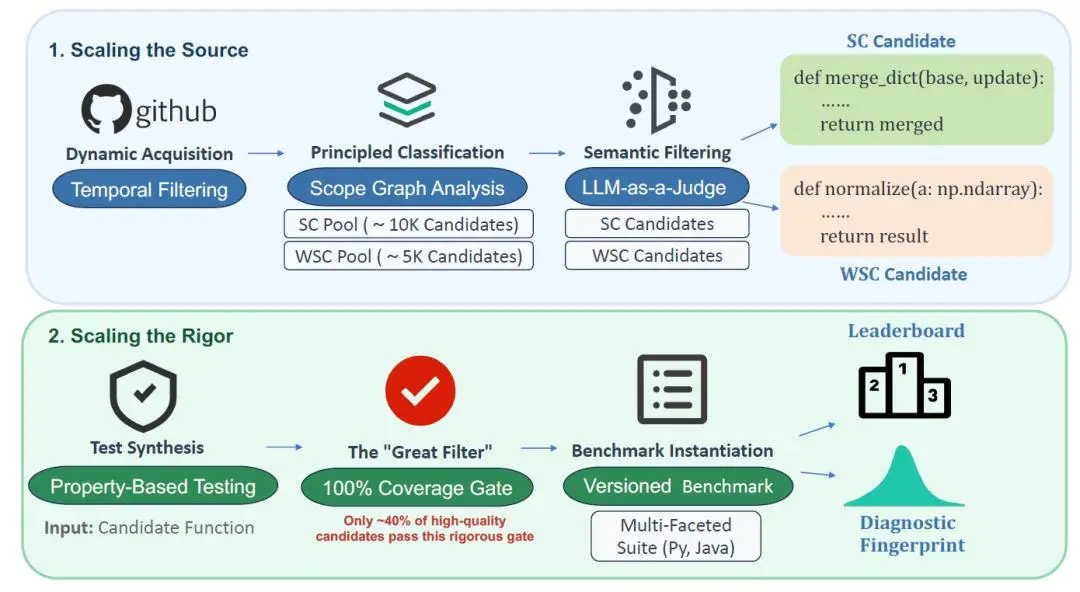
北京航空航天大学的研究团队提出了全新的解决思路,不是做一个新题库,而是建立一套自动化流水线。这套系统能持续从2025年后的GitHub活跃项目中抓取真实代码,确保题目永远新鲜,模型没法靠背诵过关。
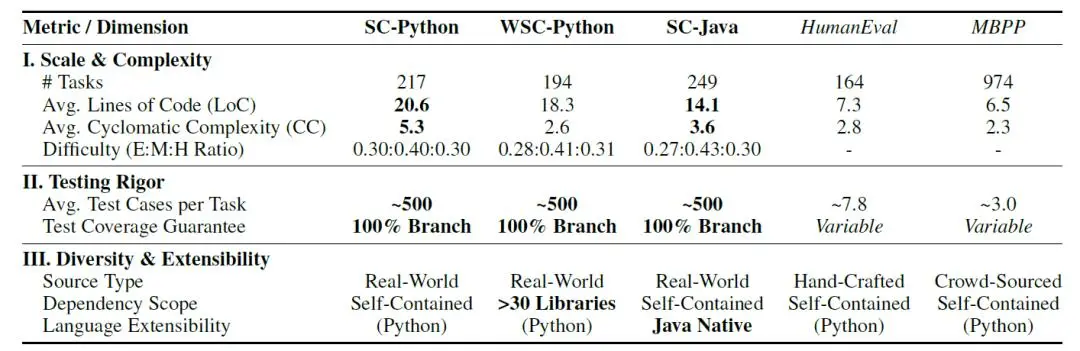
这个方法叫“双重扩展”:一方面扩展题目来源广度,从真实工程中取材;另一方面扩展测试深度,每个问题都要经受数百个测试用例的检验。只有覆盖了所有代码分支的题目才会被采用,标准极其严苛。
属性测试暴露模型短板
新框架采用了工业级的测试方法——基于属性的测试。传统测试只能验证几个点,而属性测试能自动生成成百上千的输入,覆盖典型值、边界值和各种复杂情况。模型的任何细微缺陷都无处遁形。
数据显示,在新基准的纯算法任务中,平均有6.94%的代码能通过98%的测试,却在最后几个边缘场景上失败。这些“几乎完美”的代码在传统基准里会被当成正确,但现在我们能看到,模型在逻辑鲁棒性上还有最后一公里要走。
依赖分析揭示真实开发能力

现代软件开发离不开第三方库,但传统基准很少考察这一点。新框架通过语言无关的作用域图分析,精准识别代码的外部依赖,把任务分为自包含和弱自包含两类。后者要求模型会调用NumPy、Pandas等主流库。
在构建的2509个问题基准中,弱自包含任务覆盖了30多个第三方库。测试发现,很多模型在纯算法题上表现不错,一旦涉及API调用就漏洞百出。这暴露了模型真实开发能力的严重缺陷。
指纹图谱诊断思维失效模式

得益于测试用例的量级扩展,研究人员现在能绘制出模型的“错误光谱”。不同模型在失败时的错误类型分布完全不同,这种指纹图谱能透视模型的思维失效模式。比如在复杂逻辑任务中,失败集中在逻辑错误而非API误用。
指纹图还揭示了编程语言对模型能力的影响。在静态类型语言的任务中,模型出错模式与动态语言截然不同。这说明模型的表现深度耦合于目标语言的生态系统,静态类型反而成了一种前置的鲁棒性保障。

现在的问题是,你敢把核心业务代码放心交给大模型来写吗?欢迎在评论区分享你的看法,点赞转发让更多人看到这个评测真相。