
TiDB是云原生存储解决方案中的突出代表,其分布式SQL架构在数据操控中发挥着关键作用。深入分析它的分布式SQL架构,有助于专业工作者更加娴熟地使用它,也能让管理者了解数据库行业的发展趋势。下面从几个核心方面展开深入分析。
TiDB架构组成有啥
TiDB的整体构造包含三个主要构成,分别是TiDB ,TiKV和PD集群。TiDB 属于无状态的SQL层,它负责对SQL语句进行解读,并且制定分布式执行方案,同时它也兼容MySQL的通信方式。TiKV是一种采用Raft协议构建的分布式键值数据管理核心,它确保数据具备高度一致性,同时支持横向扩容。PD集群作为整体架构中的全局元数据控制节点,负责统一管理相关配置。系统各部分在实际使用时会紧密配合,以此维持数据库的顺畅运作。
TiDB SQL如何解析
TiDB服务器接收到SQL指令后,首先会检查指令的格式是否正确,然后明确指令的具体要求。它需要根据表格的结构和数据分布这些因素,来制定最恰当的分布式执行计划。比如碰到复杂的查询,它会将任务平均分配给各个计算节点,以此来加快处理效率。
数据存储方式怎样
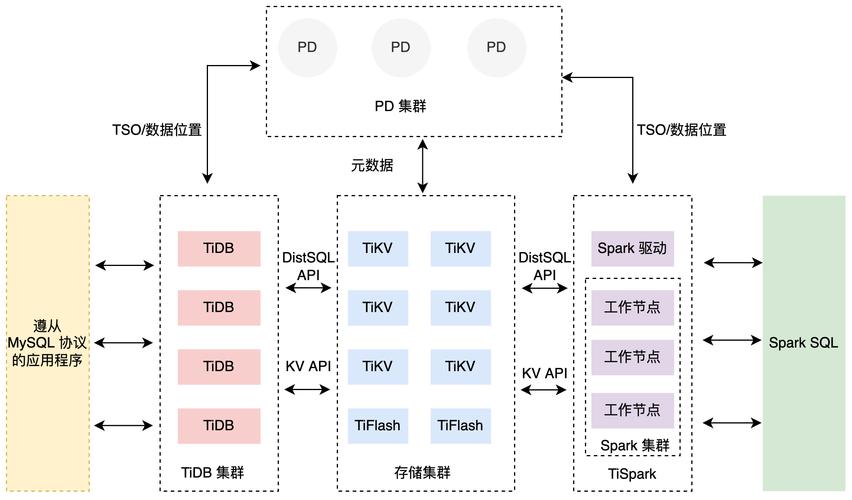
TiKV是一种分布式键值存储系统,信息分散存储在众多服务器里。它运用Raft协议,保障数据在多个副本间同步一致。数据会按照规则划分成多个部分,每个部分包含多个副本,这些副本还会分散在不同的服务器上。这种方法既能提升数据的可靠性,也便于系统进行横向扩展,满足大量数据的存储需求。
分布式执行有何优势
TiDB的分布式处理能够充分借助集群中各个节点的计算资源。面对复杂查询,系统会将任务分配给多个节点同时执行,从而大幅缩短处理时间。而且,即便某个节点出现故障,其他节点依然可以正常工作,确保系统不会停止服务。在数据量庞大的互联网环境中,这种处理方式的优势更加明显。
架构扩展性好不好
TiDB的架构非常灵活。根据实际运行情况,可以随时调整组件数量。当数据量增加,或者查询请求增多,都可以增派组件来满足需求。比如在商业促销期间,数据和查询量会急剧上升,能够快速增加组件来应对。
大家在运用TiDB分布式SQL系统时,都遇到了哪些困难?请点击喜欢,转发,在评论区分享见解,一起交流。







