
创建一个可以处理多种数据的神经网络的竞赛正在进行中——一种更通用的人工智能,它不会区分数据类型,而是可以在相同的基本结构中处理所有数据。
正如这些神经网络所称,多模态类型正在见证一系列活动,其中不同的数据(例如图像、文本和语音音频)通过相同的算法以在不同的测试中产生分数,例如 图像识别、自然语言理解或语音检测。
这些灵巧的网络在人工智能的基准测试中得分很高。 最新成果是所谓的“data2vec”,由 Meta(Facebook、Instagram 和 WhatsApp 的母公司)AI 部门的研究人员开发。
正如 Meta 研究员 Alexei Baevski、Wei-Ning Hsu、Qiantong Xu、Arun Babu、Jiatao Gu 和 Michael Auli 在博客文章中所揭示的那样,重点是接近人类思维似乎包含的一般学习能力。
“虽然人们似乎以相似的方式学习,无论他们如何获取信息——例如,无论他们使用视觉还是声音——但目前自我监督学习算法从图像、语音、文本中学习的方式存在很大差异, 和其他方式,”博客文章指出。
要点是“人工智能应该能够学习完成许多不同的任务,包括那些完全不熟悉的任务。”
Meta 的首席执行官马克扎克伯格引用了有关这项工作及其与未来 Metaverse 的联系的引述:
人们通过视觉、声音和文字的组合来体验世界,这样的系统有一天可以像我们一样理解世界。 这一切最终都将与 AI 助手一起内置到 AR 眼镜中,因此,例如,它可以帮助你做饭,注意到你是否错过了某种食材,提示你关小火候,或更复杂的任务。
data2vec 这个名字是对 2013 年谷歌开发的语言“嵌入”程序名称的一种游戏,名为“word2vec”。 该程序预测了单词如何聚集在一起,因此 word2vec 代表了为特定类型的数据(在这种情况下为文本)设计的神经网络。
然而,就 data2vec 而言,Baevski 及其同事采用了由 Ashish Vaswani 及其同事于 2017 年在谷歌开发的所谓 Transformer 的标准版本,并将其扩展为用于多种数据类型。
Transformer 神经网络最初是为语言任务开发的,但多年来它已被广泛应用于多种数据。 巴耶夫斯基等人。 表明 Transformer 可用于处理多种类型的数据而无需更改,并且经过训练的神经网络可以执行多种不同的任务。
在正式论文“data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language”中,Baevski 等人针对图像数据、语音音频波形和文本语言表示训练了 Transformer。
非常通用的 Transformer 成为所谓的预训练,然后可以将其应用于特定的神经网络以执行特定的任务。 例如,作者使用 data2vec 作为预训练来装备所谓的“ViT”,即“视觉转换器”,这是一种专门为视觉任务设计的神经网络,去年由谷歌的 Alexey Dosovitskiy 及其同事推出。
当在 ViT 上尝试解决图像识别的标准 ImageNet 测试时,他们的结果名列前茅,准确率为 84.1%。 这比去年由 Hangbo Bao 预训练 ViT lead 的微软团队获得的 83.2% 的分数要好。
同样的 data2vec Transformer 输出的结果对于语音识别来说是最先进的,并且对于自然语言学习来说即使不是最好的,也具有竞争力:
实验结果表明 data2vec 在所有三种模式中均有效,为 ImageNet-1K 上的 ViT-B 和 ViT-L 设定了新的技术水平,改进了语音识别中语音处理的最佳先前工作,并与 RoBERTa 表现相当 在 GLUE 自然语言理解基准上。
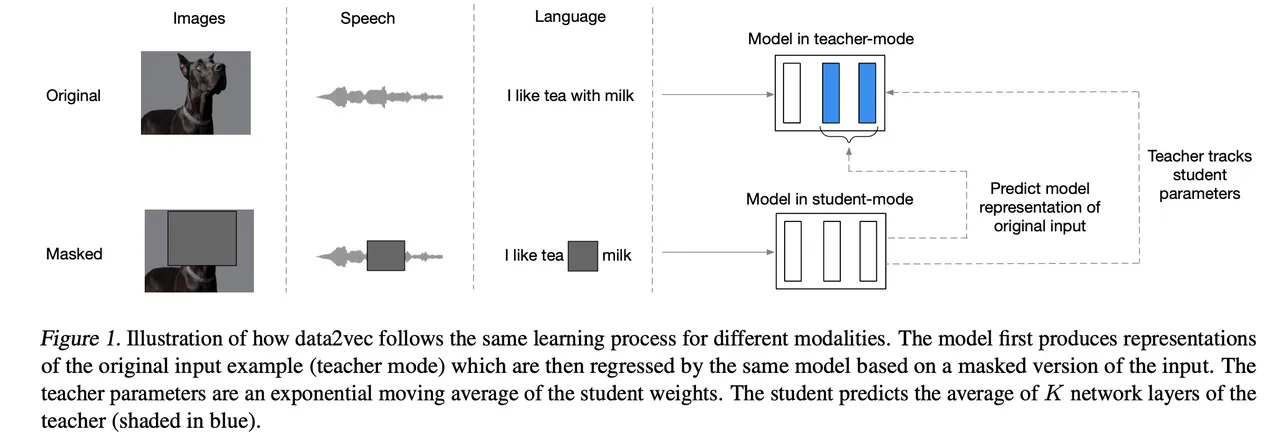
关键在于,这发生在没有对神经网络进行任何关于图像的修改的情况下,对于语音和文本也是如此。 相反,每种输入类型都进入同一个网络并完成相同的非常一般的任务。 该任务与 Transformer 网络始终使用的任务相同,称为“掩蔽预测”。
然而,data2vec 执行屏蔽预测的方式是一种称为“自我监督”学习的方法。 在自我监督的环境中,神经网络的训练或开发必须经过多个阶段。
首先,网络构建数据输入的联合概率表示,无论是图像、语音还是文本。 然后,网络的第二个版本将其中一些输入数据项“屏蔽掉”,不公开。 它必须重建第一个版本的网络构建的联合概率,这迫使它通过本质上填补空白来创建越来越好的数据表示。
这两个网络,一个具有联合概率的完整模式,一个具有它试图完成的不完整版本,被称为“教师”和“学生”,这很明智。 如果您愿意,学生网络会尝试通过重建教师网络已经取得的成果来发展其对数据的感知。
对于三种截然不同的数据类型,神经网络如何执行 Teacher 和 Student? 关键是所有三种数据情况下联合概率的“目标”都不是特定的输出数据类型,就像特定数据类型的 Transformer 版本中的情况一样,例如 Google 的 BERT 或 OpenAI 的 GPT-3。
相反,data2vec 正在抓取神经网络内部的一堆神经网络层,在中间的某个地方,代表在数据被生成为最终输出之前的数据。
正如研究人员所写,“我们的方法 […] 的主要区别之一,除了执行掩蔽预测之外,是使用基于教师网络的多层平均的目标。” 具体来说,“我们回归多个神经网络层表示,而不仅仅是顶层”,以便“data2vec 预测输入数据的潜在表示”。
他们补充说,“我们通常在每个块中的最后一个残差连接之前使用 FFN [前馈网络] 的输出作为目标,”其中“块”是相当于神经网络层的 Transformer。
关键是,对于学生网络来说,每一种输入的数据类型都面临着在教师组成的神经网络中重建某些东西的相同挑战。
这种平均不同于其他最近构建一个网络来处理所有数据的方法。 例如,去年夏天,Google 的 DeepMind 部门推出了它所谓的“Perceiver”,这是它自己的多模态 Transformer 版本。 Perceiver 神经网络的训练是生成输出的更标准过程,该输出是对标记的、受监督的任务(如 ImageNet)的回答。 在自监督方法中,data2vec 不使用这些标签; 它只是试图重建网络对数据的内部表示。
更雄心勃勃的努力正在酝酿之中。 谷歌人工智能项目负责人杰夫·迪恩 (Jeff Dean) 在 10 月份戏弄了“Pathways”,称其为用于多模态数据处理的“下一代人工智能架构”。
请注意,data2vec 对用于多种模态的单个神经网络的非常通用的方法仍然有很多关于不同数据类型的信息。 图像、语音和文本都是通过数据的预处理来准备的。 这样一来,网络的多模态方面仍然依赖于数据线索,团队称之为“小型模态特定输入编码器”。
我们还没有处在一个神经网络训练时对输入数据类型毫无意义的世界。 我们还没有达到神经网络可以构建一种组合所有不同数据类型的表示的时间点,这样神经网络就可以组合地学习事物。
ZDNet 与研究人员之间的交流清楚地表明了这一事实。 ZDNet 联系了 Baevski 和团队并问道:“作为目标的潜在表示是在任何给定时间步对所有三种模态的组合编码,还是它们通常只是其中一种模态?”
Baevski 和团队回应说是后一种情况,他们的回答很有趣,可以详细引用:
潜在变量不是三种模式的组合编码。 我们为每种模式训练单独的模型,但模型学习的过程是相同的。 这是我们项目的主要创新,因为之前在不同模式下训练模型的方式存在很大差异。 神经科学家还认为,人类以类似的方式学习声音和视觉世界。 我们的项目表明,自我监督学习也可以以相同的方式用于不同的模式。
考虑到 data2vec 特定于模态的局限性,可能真正成为一个网络来统治它们的神经网络仍然是未来的技术。



