
那天加班到凌晨三点,盯着屏幕上的报错信息发呆。
流量刚上来,服务就崩了。
实际上,我本应该更早一点儿就想到的,可具体的呢/netty的线程模型没有良好地调整好,以及配反了。
什么是高性能IM
百度上一搜,全是吹牛皮的。
什么“千万级并发”,什么“毫秒级延迟”。
别信。
高性能IM设计模式
模型,这是绕不开的。
单单线程?别想了,那是玩具。
主从具备多个的模式,才是正确的途径。其中,一个由boss组成的组负责,而多个由组成的组负责IO读写。
我的一位友人曾经历过挫折,设置了32个线程,然而队列出现了爆满的状况,真是令人忍俊不禁。
Netty在IM中的使用
说到Netty,很多人一上来就写一堆。
不对的。
非得要问为何非得把放置在最靠前的位置,因何如此放?是为了抵御防止心跳出现超时 的状况。
还有那个,使用完毕之后,可千万不要忘记,一旦出现内存泄漏,查到你都要哭出来。
我试过用池化的,性能提升30%不止。
私有协议栈设计
协议这块,太容易翻车了。
JSON?不要用。解析慢,体积大。
关于,是可行的,然而需要留意兼容性,一旦添加了新字段,老客户端会直接崩溃。
所以版本号必须放进协议头。
我的习惯呈现为,魔数,加上版本,再加上消息类型,接着是序列化类型,随后是消息ID,跟着是消息体长度,然后是扩展字段,最后是正文。合在一起总共是20个字节的头,足够了。
百万并发
那天下班后,我做了个压力测试。
单机撑到35万连接,CPU就飙到80%了。
.()阻塞了。
将其替换成NIO的r,情况好多了。
可是这还一点儿都不完全够呢。零拷贝必须得开启才行,还有mmap这两者统统都要运用起来。对于文件传输这个部分而言,性能会实现成倍的增长。
消息可靠性和ACK机制
你可能想说,UDP不是更快吗?
是的,但丢了谁赔?
所以还是要TCP。但要加应用层ACK。
对于发送方而言,其会维护一个用于等待ACK的队列,一旦出现超时情况,便会进行重传。而接收方在收到重复消息时,需要能够进行去重操作,借助消息ID以及布隆过滤器即可达成这一目的。
消息队列应用
写扩散和读扩散,想好了吗?
写扩散适合小群,读扩散适合大群。
若是有一万人的一个大群之情形,去写扩散这样的行为那便是灾难,因为,如果让每个成员都各自去写一份,那么存储方面将会被炸掉。
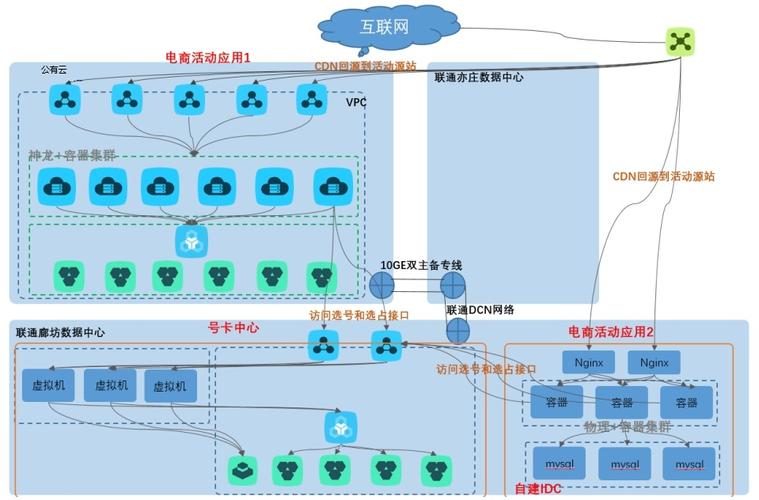
MQ于此处堪称神器,的顺序消息,可确保群聊消息不会出现乱序的情况,并且是有保证的那种。
数据库分库分表
单表存聊天记录?迟早死。
按用户ID哈希分,至少要分16张表。
热数据放Redis,过期时间设7天。
冷数据归档到TiDB,别问为什么,问就是存得下。
系统设计原则
别炫技。
堆栈越复杂,故障点越多。
KISS原则忘记了吗?
低延迟优化
有这样一个参数,通常情况下,我不会向普通人透露它,这个参数是:(true)。
Nagle算法关掉,小包立刻发。
感觉响应快了50毫秒?值了。
负载均衡算法
一致性哈希听过吗?
没听过就算了。听过的都知道什么意思。
吞吐量提升
说说我曾经的教训。
有段时间偶发性卡顿,查了三天。
最终发觉乃是由GC所引发的,对象持续进行创生,Young GC频繁被触发。
咋去处理呢?存在着对象池化这种情况。Netty的开始运用起来,去对使用过的对象给予再利用,使得GC的次数降低了90%。
消息拉取优化
推拉结合,懂的自然懂。
长轮询比普通轮询好多少?
带宽节省70%,服务器负载降一半。
为什么开源IM性能差
你可能不信,很多开源项目我都不愿意用。
不是歧视,是真不好用。
的架构还算可以,然而存在问题,用于存储消息,可是索引方面没处理好,进而导致磁盘I/O出现故障。
GoIM的代码倒是干净,功能太少。要自己往上加,不如重写。
说在最后
写IM快五年了。
踩过的坑不比吃过的饭少。
说这么多,其实就是想告诉你——理论看再多,不如动手写一次。
崩了就崩了,重启再调呗。
又加班到这个点了。
关电脑,回家。








