
好多同行问我,代码这事。大家都藏着掖着什么心理呢?
其实我想说,你们都搞反了。
到底源码算个啥
数据喂给模型,啥结果出来,自己心里都没底。
尤其刚踏进医学图像分割这行的时候。
我先说个事儿。
有个师弟,去年的时候,卡在一个病灶分割那儿,长达三个月,怎么都过不去。后来呢,找了一个开源项目,仅仅一周就搞定了。他差一点没哭出来。
这就是源码的作用。
不是你不够聪明,是你没站在前人的肩膀上。
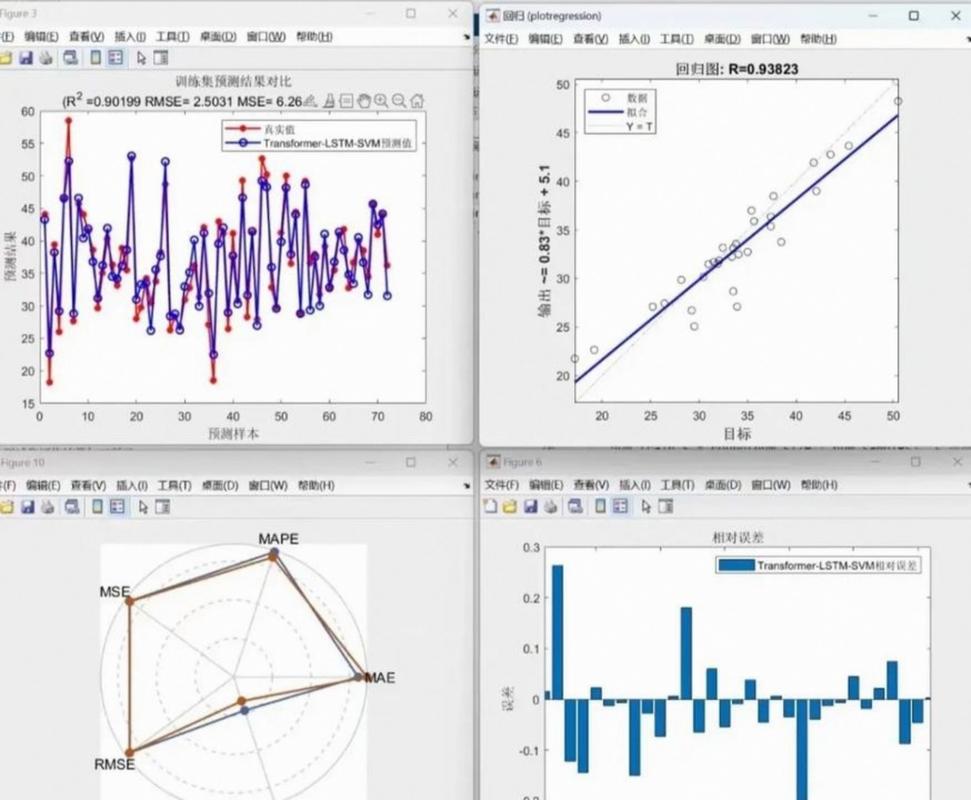
于这一行之事,我已然付诸经历达五年之时,从U – Net持续前进直至,而后又发展至Swin – Unet。说实话来讲哦,对于源码可谓即是你的另外一种意义上的大脑。
从Unet到我们经历了啥
医学图像分割这个事情,讲起来容易,是要把CT里面那些病灶区域圈出来,还要把MRI里面那些病灶区域圈出来。
但真做起来就死机。
在2015年的时候,Olaf 他们做到了U-Net的研发,那时众人认为迎来了曙光,可以尽情使用了,然而实际情况又是怎样的呢?当更换为另一个数据集时便宣告失败了,超参数需要重新进行调整,并且这一过程要耗费好几天的时间啊,简直能让人崩溃到极点。
而后,MIC-DKFZ那一群人弄出了个nnU-Net,能自动适配数据集,全然无需人工去调整参数。众人瞧见后,不禁叫道,哎呀,这难道不正是我所期望获取到的东西嘛?
致使当下摇身一变成为了标杆,在2020年举办的挑战赛当中,10个冠军里居然有9个都采用了。
这时候你还不肯开源代码?
不是傻就是坏。
一个开源项目比一个开源项目厉害,将 塞入 U-Net之中,弄出一个混合模型,其性能又提升了,Swin-Unet更为激进,直接凭借纯 重新构建整个U型架构,甚至于把CNN都舍弃了。
这就像炼金术。
别人把配方都给你了,你还非要自己从头瞎搞?
你的模型真的跑得动吗
我见过太多项目,论文牛逼轰轰,代码一泡污。
在进行训练之际,Dice Loss呈现出难以下降的态势,于验证之时,边界出现了极其严重的错误情况。
怎么回事?
评价指标,你弄清楚了吗,Dice着重于内部重合率,HD95是专门针对边界的检察官,肿瘤边界只要差了那零点几毫米,手术规划就完全废掉了,这可不是闹着玩的。
还有那些公开数据集。
针对LiTS肝肿瘤、KiTS肾脏肿瘤、BraTS脑肿瘤,在评测之际会用到这些,你是否进行了运行呢。不要跟我提及你的模型于何处堪称天下第一,敢不敢针对MSD数据集开展一次运行?
于医学图像处理此领域,不能运行的代码,等同于不存在,撰写再多篇各类不同的论文,都是毫无用处之举。
开源才是最大的闭坑指南
很多人不愿意开源,怕别人抄自己的创意。
我告诉你个更扎心的真相。
处于当下医学图像分割这个领域方向之中,其技术已然是相当成熟的状态了。nnU – Net如此一种框架在23个具有权威性的数据集中均可摘得高分,且是全程自动进行配置的。而你却无论如何坚决不肯与其他人进行分享,这就等同于自己关起门来造车,最终必然只能面临被淘汰的结局。
大模型时代都来了,SAM这种基础模型都能做零样本分割了。
你还在纠结要不要给人看代码?
这不是搞笑吗?
放下心来,将你的模型释放出来,让人去指责你的边界划分得不够细致,让人诉说你Dice指标并非最为优秀。
有问题才有进步。
技术就是这样迭代的。
底气拿着了源码,才能够跟别人去说,于他们而言,这个肿瘤分割的效果不太好,是由于X、Y、Z这样的原因所导致的,随后大家一块去想办法,把这个问题给解决掉。
这才是正道。
给自己留个台阶
写到这里,我想说。
医学图像分割这个赛道,谁都不敢说自己一定是第一名。
但如果你连源码都不敢开源,那连参赛的资格都没有。
真的。
最重要的并非输赢,而是你有勇气站出来,将你写出的那些并非极善极美的代码展示出来,去接受这个行业最为严苛且最为公正平允的检验。
好似我们进行CT检查那般,一层一层地扫描过去啊 ,把看到的病灶给圈出来, 朝着它直面相向句号。
别因为怕输就把源代码藏起来。
赛事归赛事讲,然而身为医学可是无止境范畴。将自有代码呈供出来,哪怕仅仅是对一位读研中的师弟起到助力作用,哪怕仅仅是对一名在偏远区域从事治病工作的医生提供某种助益,如此这般你的代码便不算未有效编写。
这条路,大家一起走,比一个人走,要快得多。
开干吧。








