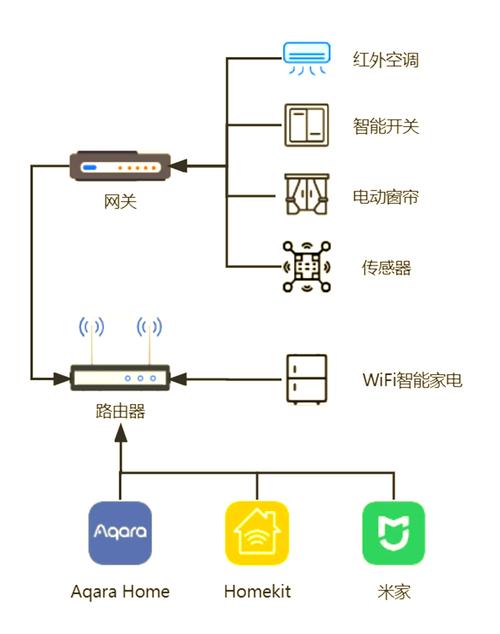
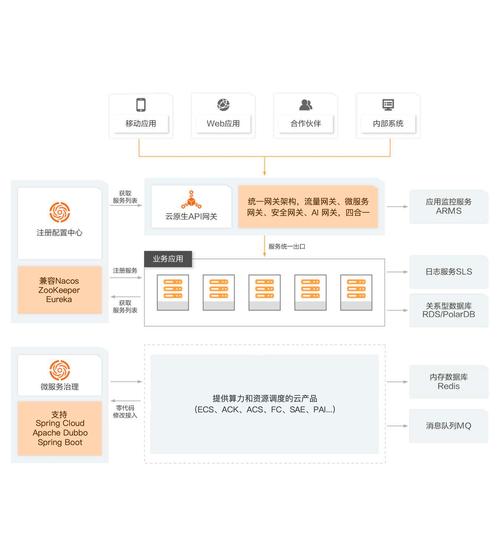
联邦查询是当下API开发中不可忽视的技术方案。它将的灵活性与分布式数据源统一起来,让前端能像调用单个接口一样获取跨服务数据。我观察到许多团队在处理多微服务聚合时遇到性能瓶颈,而联邦查询正是解决这类痛点的利器。
什么是联邦查询
简单说,联邦查询允许你把多个子图合并成一个统一的超级图。开发者无需关心数据到底来自订单服务还是用户服务,只需在查询中声明需要哪些字段,网关会自动拆分请求并聚合结果。这大大降低了前端与后端的协作成本。
实践中,你可以通过声明式配置定义各个子图的依赖关系。内置了智能查询规划器,它会分析你的操作,生成最优的跨服务数据抓取计划。相比传统聚合层,联邦查询能减少网络往返次数,提升响应速度。
联邦查询如何提升性能
性能优化是引入联邦查询的核心动机之一。当查询跨越多个微服务时,会并行执行子查询,而不是串行等待。例如获取订单详情及用户信息,系统会同时向订单服务和用户服务发起请求,总耗时取决于最慢的那个服务。
另外,联邦查询支持实体解析器的批处理功能。如果订单列表中有多个相同用户ID,会自动合并成一次批量请求,避免N+1问题。这在处理大数据量场景下效果尤为明显,实测某些复杂查询的响应时间可以从秒级降至毫秒级。
联邦查询的落地难点
实施联邦查询并非没有挑战。首先需要为每个子服务定义实体和引用键,确保不同服务能正确关联数据。如果服务间存在循环依赖或字段冲突,联邦网关的配置会变得复杂。团队必须建立统一的字段命名规范。
同时,联邦查询的调试难度比单体高。错误可能来自任意子图,追踪问题需要跨服务日志链路。建议你从一开始就集成分布式追踪系统,并利用自带的操作分析面板来监控查询效率。只有充分准备,才能发挥联邦查询的真正价值。
你在使用联邦查询时遇到最头疼的问题是什么?欢迎在评论区分享你的实战经验,点赞让更多开发者看到这份干货。