在日常的大数据开发中,作业的准时、可靠运行往往是保障数据链路稳定的基石。作业调度器作为一款轻量级但功能强大的分布式调度工具,它解决了传统难以管理复杂依赖和单点故障的痛点。本文将从实际使用角度,带你快速掌握的核心价值与操作要点。
作业调度器是什么
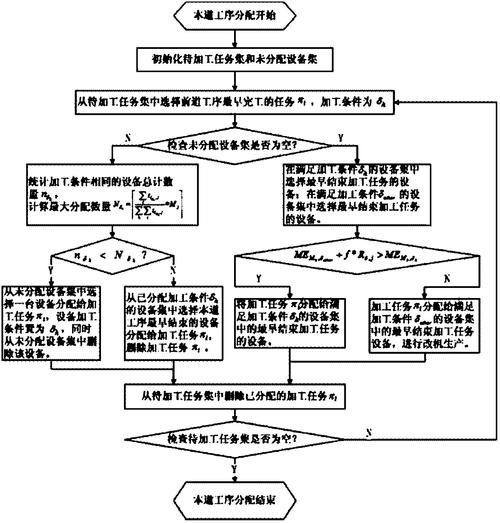
简单来说,是一个基于时间与事件触发的分布式作业调度系统。它与普通定时脚本最大的区别在于,提供了统一的作业定义、依赖管理和失败重试机制。当你面对几十个互相依赖的Spark或Flink任务时,能帮你清晰梳理上下游关系,避免手动串接带来的延迟或漏跑问题。它原生支持作业的DAG可视化,让整个数据流向一目了然。
如何配置依赖关系
配置的作业依赖主要通过声明式的YAML文件完成。你只需在作业定义中指定字段,列出前置作业的ID,调度器就会自动解析并构建执行顺序。例如,ETL清洗任务需等待数据导入任务成功完成,会确保上游任务每个实例都达到终态(成功或跳过)后,才触发下游任务。实际使用时,建议为关键路径设置合理的超时与告警,避免单个任务阻塞整个链路。
失败重试与监控策略
提供了灵活的重试机制,支持指数退避和固定间隔两种模式。你可以在作业级别设置最大重试次数(如3次)和重试间隔(如5分钟)。对于瞬态错误(如网络抖动、资源队列满),重试能极大提升任务最终成功率。同时,集成了指标接口,能实时暴露作业排队数、运行时长、失败率等关键指标。建议团队统一配置看板,当作业连续失败超过阈值时,通过钉钉或邮件及时告警。
与对比选择
很多团队会纠结于选还是。如果你的场景主要是海量短任务(秒级或分钟级)且对调度器自身资源占用敏感,更轻量。它的核心组件只有一个调度器进程,无数据库依赖,部署和运维成本远低于。但若你需要复杂的条件分支、传感器模式或丰富的数据源插件,生态更成熟。建议小团队或任务量在500以内的场景优先尝试。
你目前的数据任务中,最让你头疼的是依赖管理混乱还是任务频繁失败?欢迎在评论区分享你的调度实战经验,点赞收藏本文,帮助更多同行避坑。