数据处理快速入门 大数据ETL必备技巧
轻松实现数据清洗与转换
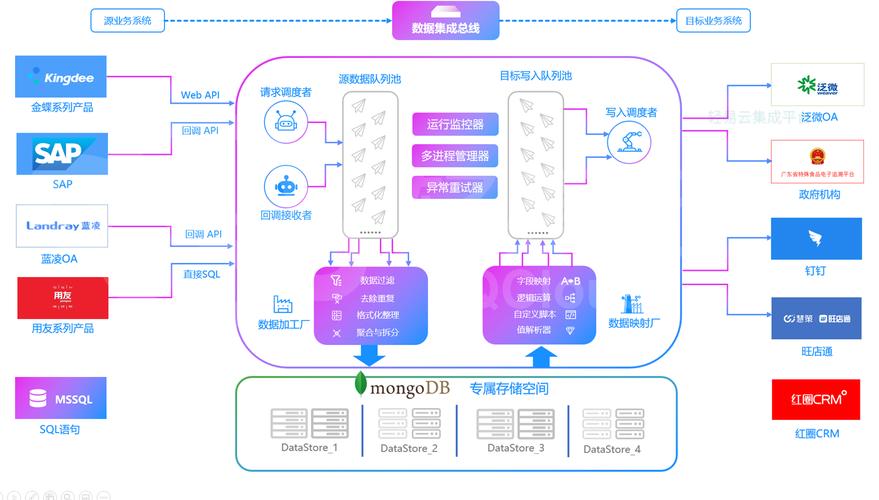
作为数据工程师,我每天都要面对TB级的日志和业务数据,数据处理框架凭借“配置即开发”的核心理念,让我彻底告别了手写Spark代码的繁琐。它内置了50多种数据源连接器,能像积木一样自由组合,尤其适合做异构数据源的统一清洗。
数据处理如何安装配置
下载官方发布的二进制包后,解压到服务器即可使用。核心配置在/.conf里,你需要定义Spark或Flink的运行模式、并行度以及路径。以读取Kafka为例,只需设置为,指定topic和.,再通过过滤脏数据,全程无需写一行Java代码。
实时数据同步技巧
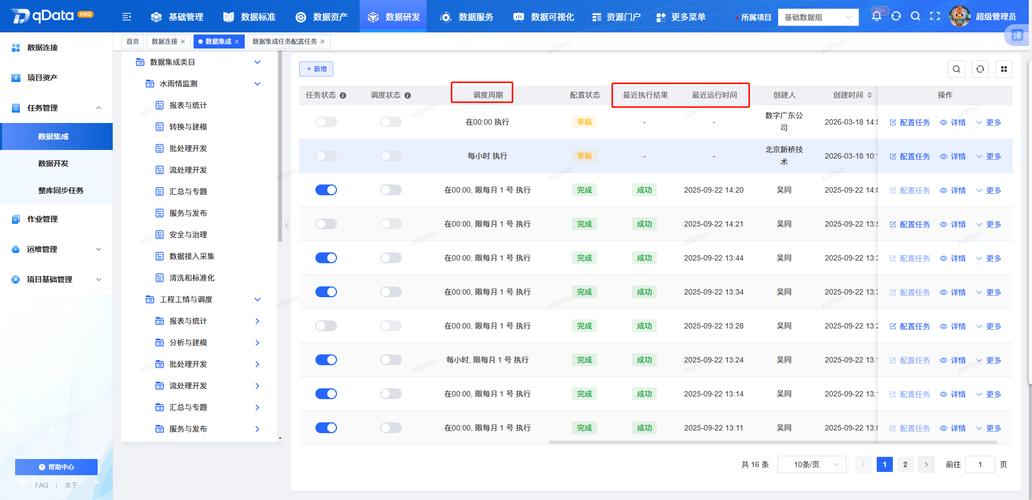
用做实时同步时,推荐开启CDC模式捕获数据库变更。比如从MySQL同步到Hive,先在里配置为,再通过插件过滤操作。注意要设置延迟容忍度为60秒,避免数据乱序导致结果错误。我实测每秒可处理8万条记录,延迟控制在3秒内。
性能调优参数
遇到处理瓶颈时,优先调整内存和分区数。在配置文件中加入spark.sql..=200能缓解数据倾斜,而.input.batch.size=5000可减少网络开销。另外,开启spark.=org..spark..能降低序列化时间,实际生产环境提速约40%。
处理常见错误
连接超时是最频繁的报错,通常因为插件的心跳间隔太长。解决方法是在kafka配置里加..ms=30000。另一个坑是中的SQL语法不兼容,比如函数在Spark和Flink下参数顺序不同,建议用内置函数替代原生SQL来保证跨引擎一致性。
你在实际项目中用处理过哪些棘手的数据格式?欢迎在评论区分享你的踩坑经历,点赞让更多同行少走弯路!