开源数据集成工具是当前企业ETL领域的热门选择,它以开源免费、图形化开发、组件丰富等特点,帮助数据工程师快速搭建数据管道。无论你是要做数据迁移、数据仓库构建,还是实时同步,都能提供低成本、高灵活性的解决方案。下面我从三个核心问题出发,带你深入理解这个工具的实际价值。
开源有什么优势
成本优势最为突出。社区版完全免费,企业无需投入数十万的软件授权费,就能拥有企业级的数据集成能力。相比商业ETL工具,大幅降低了中小企业的起步门槛,让你可以用有限的预算完成复杂的数据整合任务。组件生态极其丰富。内置超过1000个连接器和处理组件,覆盖主流数据库、云存储、API、消息队列等。无论是读取MySQL数据,写入,还是调用REST接口,拖拽组件就能完成,省去大量手写代码的时间。
如何快速上手开源
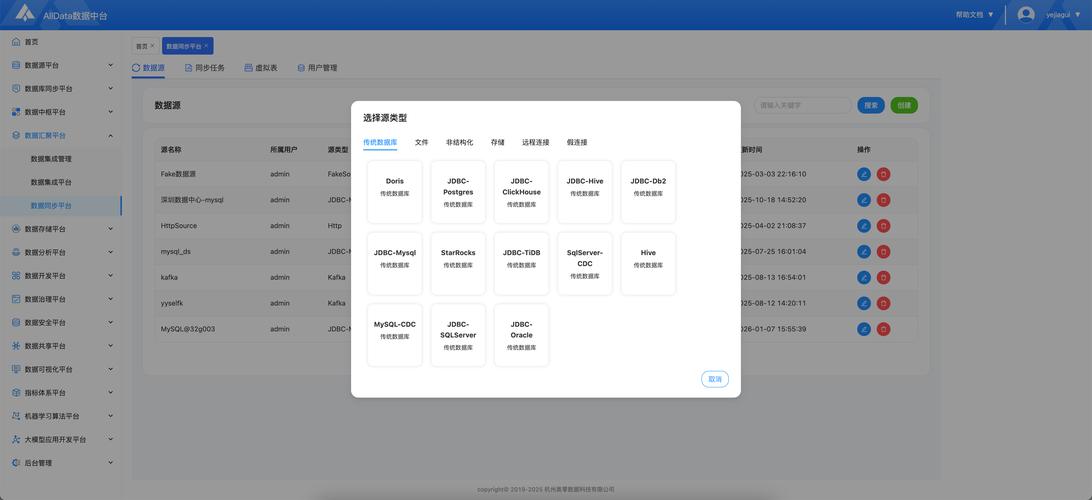
下载安装 Open ,这是一个基于的可视化IDE。打开后新建Job,左侧面板列出了所有组件,比如用于读取数据库,用于写CSV文件。把组件拖到设计区,用连接线串联起来,就构成了数据流。双击组件配置连接信息和操作逻辑。例如在中填写数据库地址、用户名、密码,再写一句查询。点击运行按钮,数据就会从源端流向目标端。整个过程无需编写Java代码,官方提供详细的教程和样例工程,新手在一小时内就能完成第一个同步任务。
开源适合哪些场景
数据仓库批量同步是最常见的应用。你可以定期将业务库中的订单、用户等表抽取到数仓ODS层,利用tMap组件做字段映射、类型转换和简单清洗。数据迁移同样得心应手,比如从迁移到,或者从本地数据库迁移到阿里云OSS。对于实时集成需求,可以结合Kafka组件实现CDC数据订阅。此外,数据质量提升也是强项。使用ck组件自动校验字段格式,配合去重,快速产出高质量数据集。生成的原生Java代码还能直接提交到Spark集群运行,轻松应对海量数据处理。
你在实际使用开源数据集成时,遇到过最棘手的性能问题或组件兼容性坑点是什么?欢迎在评论区分享你的实战经历,点赞让更多数据同行看到这份指南。