
在云数据集成领域,凭借其原生云架构和可视化操作,正成为越来越多企业的首选ETL工具。而“转换”作为ETL的核心环节,直接决定了数据质量和分析价值。本文将从实际工作场景出发,分享几个关于 ETL转换的实用技巧,帮助大家少走弯路。
什么是 ETL转换的核心组件
的转换组件主要分布在“”菜单下,包括聚合、筛选、连接、联合、行生成器等。与传统ETL工具不同,将每个转换动作封装为独立的组件,用户通过拖拽和配置即可完成复杂逻辑。例如,想要实现SQL中的GROUP BY,只需使用“聚合”组件并指定分组字段和聚合函数。理解每个组件的适用场景,是提升转换效率的第一步。
如何优化中的慢速转换任务
面对百万级以上的数据量,转换任务很容易出现性能瓶颈。常见的优化手段包括:优先使用“数据库端转换”组件(如SQL ELT组件),让计算在数仓内完成;减少“样本”组件的大范围扫描;合理设置“运行循环”的并发数。另外,利用的环境变量动态调整批处理大小,也能显著改善大表连接场景的执行时间。建议在开发阶段就用真实数据规模测试性能。
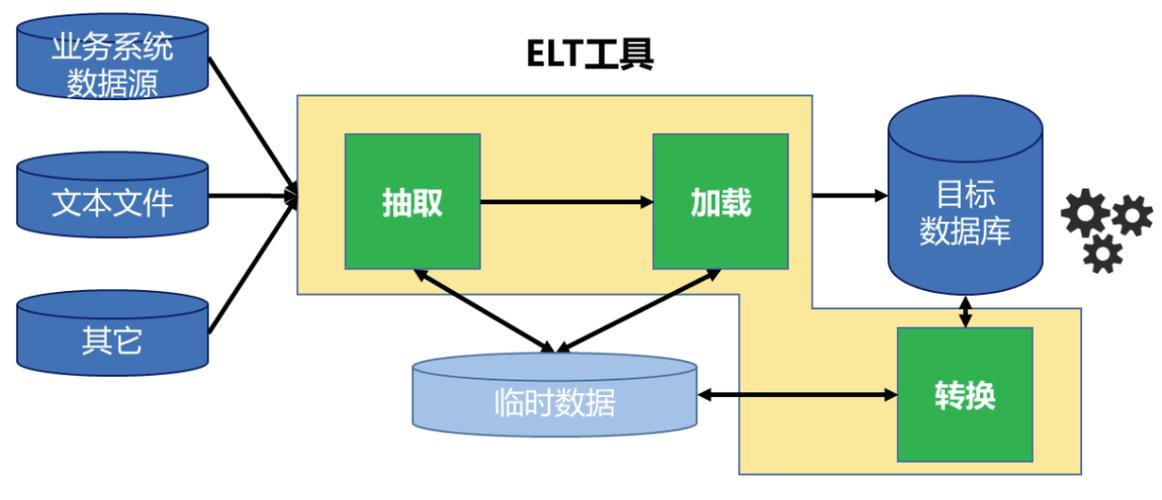
ETL转换时如何处理脏数据
数据清洗是转换阶段最繁琐的工作。提供了“筛选行”和“计算列”组件来识别异常值,配合“替换列”组件修正错误格式。对于复杂的脏数据模式,可以调用或Shell脚本组件进行正则匹配。一个实用的技巧是:先用“样本”组件抽取少量数据,快速迭代清洗逻辑,再应用到全量。同时,建立“异常数据分流”模式,将不合规的数据写入单独表,避免阻塞主流程。
怎样用变量实现动态转换逻辑
的环境变量和作业变量能让转换流程灵活起来。比如,根据当前日期自动处理增量数据,只需在“增量更新”组件中引用变量${}。再比如,通过“条件判断”组件结合布尔变量,可以动态跳过某些转换分支。更高级的用法是在“执行SQL”组件中动态拼接表名或字段名,实现多租户数据拆分。掌握变量作用域和赋值时机,是构建可复用转换作业的关键。
你平时在 ETL转换中最头疼的性能问题是什么?欢迎在评论区分享你的经验,一起交流让数据加工更高效。








