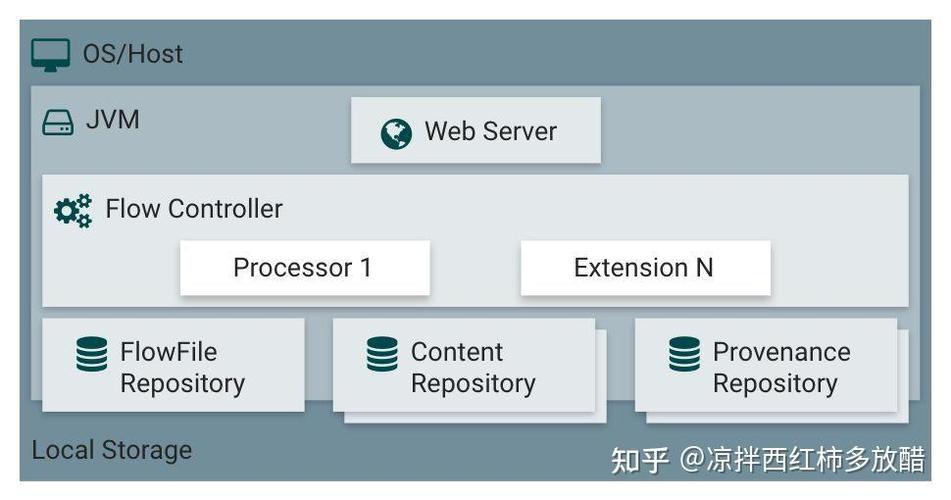
作为云端数据仓库,性能调优是每个数据团队都绕不开的课题。很多用户发现,随着数据量和查询复杂度上升,集群响应越来越慢,资源消耗却居高不下。其实,大多数性能瓶颈都源于表设计、排序键、分布键和SQL写法四个环节。只要抓住这些关键点,就能让查询速度有质的提升。
如何分析慢查询
首先你要学会定位真正的慢查询。不要凭感觉猜测,而是直接查看系统表和,找出执行时间最长的SQL。重点关注那些扫描行数巨大、返回行数很少的查询,它们往往缺乏有效过滤条件。另外,观察警报和可以判断是否发生了排队或资源竞争。
怎么优化表设计提升性能
表设计是性能的根基。你要根据查询模式选择合适的排序键和分布键。排序键让数据按顺序存储,能极大加速范围查询和关联操作。分布键决定数据如何切片到各个节点,选错会导致大量数据重分布。同时,避免使用宽表,尽量将经常一起查询的列放在同一张表中,并定期执行和维护统计信息。
为什么需要维护排序键
排序键不是一劳永逸的。随着数据不断插入和更新,原有的物理顺序会逐渐混乱,导致查询时需要扫描更多数据块。你需要建立定期维护计划:在大量数据加载后运行 SORT ONLY重建排序,同时运行更新统计信息。对于时序数据,可以按日期字段做复合排序键,让最新数据优先访问。
怎样设置分布键减少数据移动
分布键决定了查询时的数据移动成本。最理想的分布键是经常用于JOIN和GROUP BY的列,能让相关数据预先放在同一节点。如果分布键选择不当,会触发广播或重分布,大量数据在节点间传输,严重拖慢查询。你可以检查和系统表,看是否存在不合理的数据移动,然后调整分布策略为KEY、EVEN或ALL。
你在实际调优时,遇到的最大瓶颈是表设计还是SQL写法?欢迎在评论区分享你的经验,觉得有用就点个赞吧。