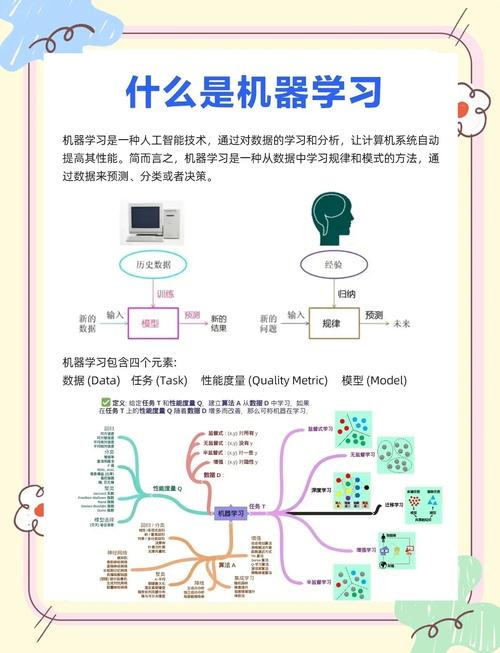
为数据工程师提供了在内直接使用进行大规模数据处理的强大能力。它让开发者能够将复杂的转换逻辑推送到数据平台内部执行,显著提升开发效率和运行性能。
开发环境如何配置
首先需要安装 库,通过pip –命令即可完成。接着要配置连接参数,包括账户标识符、用户名、私钥或密码。建议使用密钥对认证方式增强安全性。连接成功后,通过.创建会话,这是所有数据操作的基础。另外,别忘了设置角色和仓库,它们决定了可访问资源和计算能力。
数据转换怎样用实现

与传统不同,它采用惰性求值机制。当你调用、或时,这些操作只是构建了执行计划,直到调用或count才会触发实际计算。这种设计能自动优化查询,减少数据移动。例如处理亿级日志数据,你可以链式调用多个转换方法,会将其编译为单个SQL语句下推执行。
UDF开发有哪些性能技巧
自定义函数允许你嵌入业务逻辑,但需注意序列化开销。优先使用内置函数和向量化UDF,它们能以批处理方式运行,大幅降低逐行调用成本。对于复杂算法,可以注册临时UDF并指定返回类型和输入类型。同时利用的缓存机制,将中间结果持久化,避免重复计算。实测表明,合理使用UDF能让任务提速3到5倍。
看到这里,你在实际 开发中遇到过最棘手的性能瓶颈是什么?欢迎在评论区分享你的踩坑经历,点赞让更多开发者看到这些实战经验。