作为一款开源的数据目录工具,正被越来越多数据团队用来解决“数据沼泽”难题。它通过搜索、血缘追踪和元数据管理,帮助工程师和分析师快速找到所需数据表,大幅提升数据发现效率。本文将带你深入了解的核心价值、部署方法及适用场景。
数据目录是什么
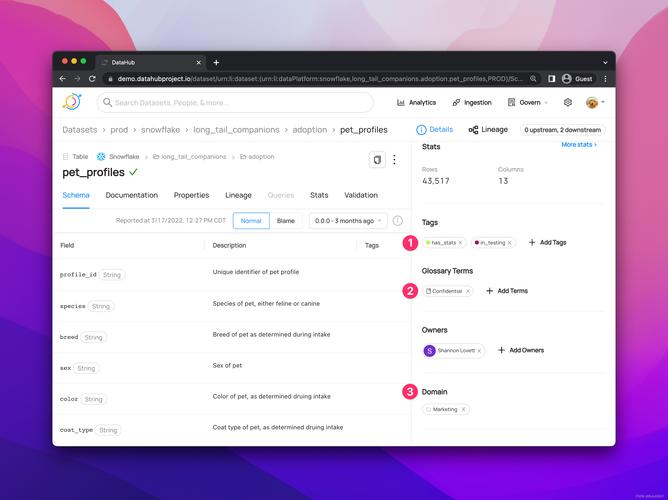
最初由Lyft开发并开源,专注于数据发现和元数据管理。与传统数据目录不同,它提供了类似搜索引擎的简洁界面,用户只需输入关键词就能找到相关数据表、字段甚至仪表盘。其底层依赖、Neo4j和元数据数据库,通过爬虫从Hive、等数据源自动收集元数据。
数据目录有什么用
主要解决三个痛点:找表难、理解字段含义难、评估数据质量难。比如分析师接手新项目,不知道“”来自哪张表,通过搜索就能看到表描述、字段血缘和最近使用频率。此外,它还能展示列级血缘,清楚告诉你某个聚合字段是如何从原始表计算出来的,避免误用脏数据。
数据目录怎么部署
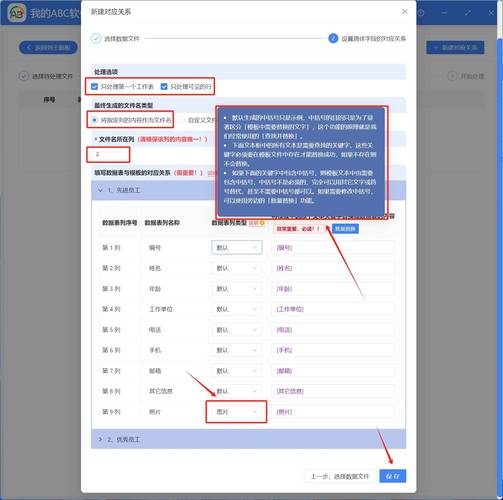
部署可以采用官方 快速体验,生产环境建议使用。核心组件包括:前端应用、元数据服务、搜索服务和数据提取器。你需要配置元数据数据库()、图数据库(Neo4j)和搜索后端()。提取器支持对接AWS Glue、、等,通过定期运行爬虫任务同步元数据。
数据目录值得选吗
与 Atlas或相比,更轻量,对数据发现场景优化极佳,但血缘展示不如细致。如果你的团队主要痛点在于“找表难”,且希望快速上线,是不错的选择。不少中小型公司已经在生产环境使用,社区维护活跃,文档也比较完善。不过要注意,它暂不支持数据质量告警,需要搭配其他工具。
你们公司在数据发现或元数据管理上遇到过哪些坑?欢迎在评论区留言讨论,觉得有用别忘了点赞分享。