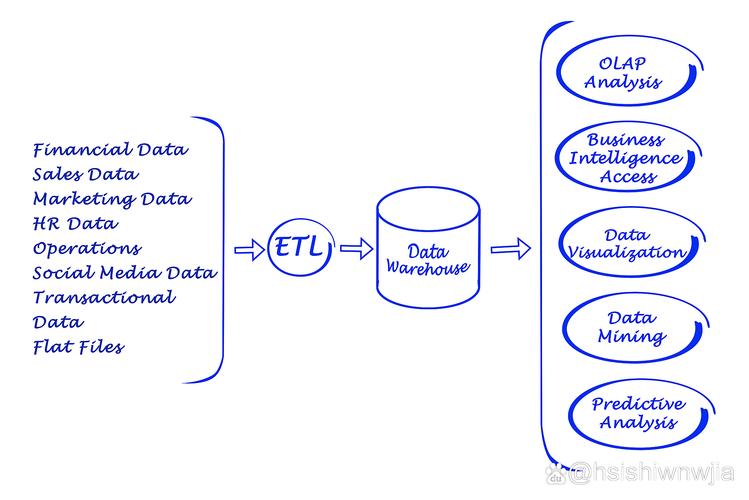
面对海量数据的实时分析需求,传统数据库常常显得力不从心。分布式SQL引擎正是为解决这一矛盾而生,它融合了NoSQL的扩展性与标准SQL的易用性,为现代数据驱动型应用提供了一个高性能、高可用的查询层。本文将从实际应用角度,剖析这一引擎如何帮助我们打破数据孤岛,实现查询速度的飞跃。
水平扩展能力怎么样
的核心竞争力在于其原生分布式的架构。它摒弃了传统数据库分库分表的繁琐中间件,采用了对等节点的设计理念。当数据写入时,系统会自动将数据分片并均匀分布到集群所有节点上,同时创建多个副本保证高可用。这意味着,当业务量增长时,我们只需简单地增加节点,系统的存储容量和查询吞吐能力就能实现近乎线性的提升,彻底摆脱了单机数据库的性能天花板。
在实际运维中,这种架构带来的好处是实实在在的。比如在物联网场景下,面对千万级设备每秒产生的海量时序数据,集群可以轻松通过横向扩展来应对。所有节点都能参与查询计算,多核并行处理,让复杂聚合分析也能在毫秒级完成。这种无需停机、动态扩容的能力,为业务的敏捷迭代提供了坚实的基础设施保障。
如何利用提升查询性能
要充分发挥的威力,关键在于用好其专为搜索和分析优化的索引机制。它在每个数据分片上都内置了类似的倒排索引,这意味着无论数据量如何膨胀,对特定字段的过滤和排序都能保持极快的响应速度。在表结构设计时,我们可以将高频查询的字段定义为类型并建立全文索引,或者利用其强大的类型来处理半结构化数据,这比传统的关系模型更加灵活高效。

除了索引,还提供了丰富的查询优化手段。例如,通过 BY对海量数据进行分区裁剪,可以大幅减少查询需要扫描的分片数量。同时,其独有的JOIN策略在分布式环境中也经过了特殊优化,鼓励用户通过“将数据放置于一处”的范式,利用嵌套来减少跨节点关联,从而将复杂的多表关联转化为单表查询,这往往是实现亚秒级响应的关键技巧。
常见应用场景有哪些优势
在需要快速响应的数据密集型场景中表现尤为突出。在工业物联网领域,它常被用作实时监控与预测性维护的数据后端,能够轻松消化高频传感器数据,并支持复杂的窗口函数和地理空间查询,帮助工程师快速定位异常。在电商和广告科技行业,它则能作为实时用户画像和行为分析的引擎,在高并发下对用户进行毫秒级的精准圈选和指标聚合,直接支撑实时推荐系统。
的“大众化”SQL接口大幅降低了技术门槛。它允许开发团队无需学习复杂的NoSQL查询语法,就能利用熟悉的SQL工具链进行数据操作。与Kafka、Spark等大数据生态组件的良好集成,也使其能无缝嵌入现有数据管道。这种既能处理海量数据,又能保持开发效率的特性,让它在需要快速迭代的初创公司和追求降本增效的传统企业中,都找到了广泛的用武之地。
在您的业务实践中,是否也遇到过因数据量增长而导致的查询性能瓶颈,您认为这种融合了搜索与分析能力的分布式SQL引擎,能为您解决哪些最棘手的难题呢?欢迎在评论区分享您的看法。