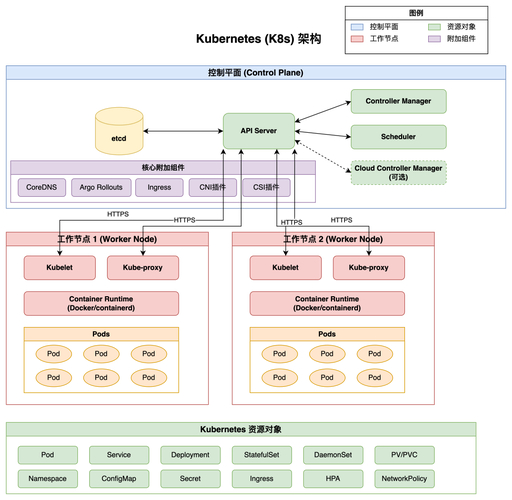
在微服务和云原生架构日益复杂的今天,应用性能问题往往像幽灵般难以捉摸。传统监控只能看到CPU、内存的表面指标,却无法回答“代码到底在哪一行变慢”这个核心问题。持续剖析技术正是为了填补这一空白而生,而作为开源持续剖析领域的佼佼者,让开发者能以极低成本获得代码级别的性能洞察,真正做到让性能优化有据可依。
持续剖析到底解决什么痛点
传统性能分析工具往往只能采集瞬时快照,就像在高速公路上用照相机抓拍,很难还原交通拥堵的全过程。而持续剖析以固定的高频率对应用进行采样,形成一条完整的时间线性能曲线。当你发现服务响应变慢时,可以回溯到任意时间点,精准定位是哪个函数、哪一行代码占用了过多资源。这种能力在定位间歇性故障、周期性性能抖动时尤为关键,彻底告别“复现不了”的困境。
核心优势有哪些
最大的亮点在于其极低的开销和友好的用户界面。通过采用原生eBPF技术或高效的采样代理,它在生产环境下的额外负载通常低于5%,完全可接受。同时,它支持Go、Java、、Ruby等主流语言,并能与无缝集成,让你在现有监控大盘中直接查看火焰图。更重要的是,采用标签化数据模型,可以按服务、版本、地域等维度灵活聚合,帮助团队快速定位是哪个新版本引入的性能回退。
如何快速上手
上手只需三步:部署服务端、集成SDK、查看数据。首先通过Helm或一键启动服务端,它内置了存储和查询接口。接着在你的应用中引入对应语言的SDK,通过几行代码配置应用名称和标签。启动应用后,数据便会自动上报。你可以在Web UI中看到实时生成的火焰图,任意框选时间段,即可对比不同时期的性能差异。整个过程无需修改业务逻辑,非侵入式的设计让落地成本极低。
在实际生产环境落地时,你会惊讶于那些被长期忽视的性能盲区。持续剖析不仅是一种工具,更是一种将性能管理常态化的方法论。你在优化应用性能时,遇到过最棘手的“疑难杂症”是什么?欢迎在评论区分享你的故事,一起交流排查思路。