一、实时数据分析的核心能力概述
Doris 作为一款开源的现代化实时分析型数据库,其设计的核心目标之一是提供极致的数据新鲜度。它将数据分析的延迟从传统模式的天级、小时级压缩至秒级,能够满足数据从产生到可查询1秒以内的严苛要求 。
对于实时数据分析而言,本质意图在于动作执行与信息查询的结合。用户不仅需要知道“Doris是什么”,更需要明确“如何用Doris实现实时分析”。本文旨在提供一套完整的操作指南,覆盖从数据接入、模型设计、更新机制到性能优化的全链路解决方案。
二、核心数据模型选型:主键模型( Key)是实时分析的基石
在 Doris中,表模型决定了数据的存储与更新行为。针对实时数据分析场景,主键模型是唯一推荐的模型,它是实现复杂、高频数据更新的核心 。
| 表模型 | 主要特点 | 实时分析适用性 | 适用场景 |
|---|---|---|---|
| 主键模型 | 支持行级(更新/插入)和部分列更新,提供极强的一致性 | 极高 | 订单状态实时同步、用户标签实时计算、CDC数据同步 |
| 聚合模型 | 预聚合,相同Key的数据进行SUM/MAX/等合并 | 低 | 实时报表汇总(如PV/UV统计) |
| 明细模型 | 仅支持追加写入,无法更新历史数据 | 极低 | 日志采集、行为埋点(无需更新) |
1. 关键机制:写时合并(Merge-on-Write)
自 Doris 2.1 版本起,主键模型默认采用写时合并(MoW)机制。该机制在数据写入时即完成去重和合并,确保存储中每个主键只有一条最新记录 。
查询性能:查询时无需额外合并操作,性能接近明细表,耗时相比读时合并(MoR)减少3-10倍 。
写入性能:写入时因合并操作有约10%-50%的性能损失,但换取了极致的查询体验。
选择建议:绝大多数实时更新场景(读多写少)选择MoW;仅当写入负载极高且对查询延迟不敏感时,才考虑旧版的MoR。
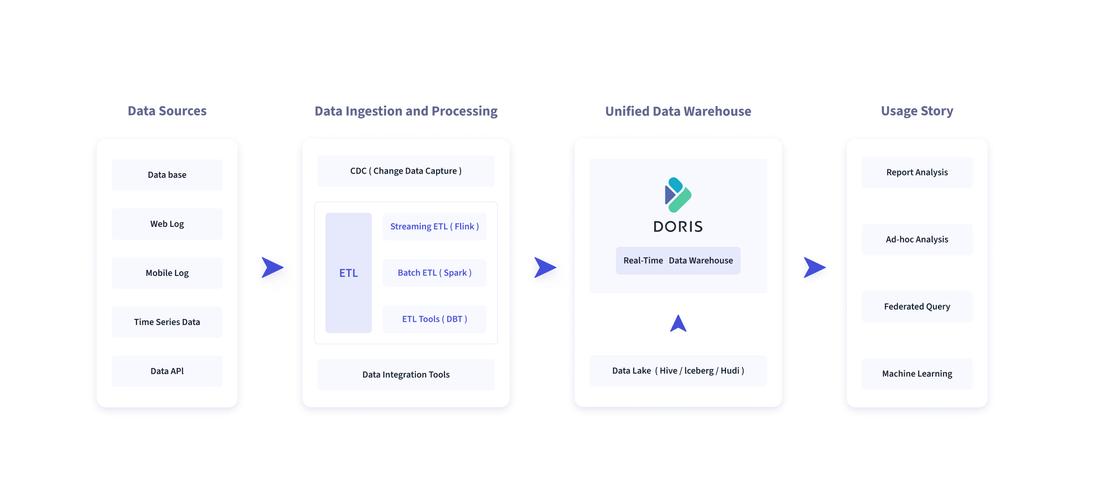
三、全链路实时数据接入方案
为了实现数据的“秒级可见”,Doris提供了多种高性能的数据导入方式,用户可根据数据源特征选择:
1. 实时流数据同步(Kafka):使用 Load 功能。它通过HTTP拉取Kafka数据流,支持CSV和JSON格式,能持续将消息队列中的数据毫秒级写入Doris 。
2. 高并发点查写入:对于TP数据库CDC同步或高频业务数据,推荐启用 Group 并配合JDBC 或 Load。这能将高频小批量写入合并为大事务提交,显著提升吞吐量 。
3. 事务数据库同步:使用 Flink Doris 或 Datax 直接对接MySQL、等数据库的CDC数据流,实现数据的实时捕获与同步 。
四、实时数据更新的核心技术与操作指南
1. 语义(导入即更新)
Doris的所有导入方式( Load、 Load、 Load、 INTO)天然支持 语义 。
操作:导入数据时,若数据主键已存在,系统自动用新行覆盖旧行;若不存在,则插入新行。
示例:
使用 INTO进行
INTO (, , ) (1001, '', NOW());
如果=1001已存在,则更新和;否则插入新记录
2. 部分列更新( )
针对宽表场景(如用户画像),无需每次更新整行所有字段。Doris 2.0+版本支持部分列更新,仅需在导入时指定主键和待更新字段 。
操作前提:建表时开启"" = "true"。
效果:极大地简化了ETL流程,避免了读取整行数据再写回的开销。
3. 乱序数据处理:列
在分布式环境中,数据乱序到达是常见问题(例如旧状态数据晚于新状态到达)。Doris通过 列 机制保证最终一致性 。
机制:建表时指定一列(通常是时间戳)作为版本依据。当主键相同时,Doris永远保留列值最大的数据行。
建表示例:
TABLE (
,
,
)
KEY()
("." = ""); -- 指定版本列
4. 数据删除
高效批量删除:通过导入时增加隐藏列 _ 进行标记删除,适用于主键模型。
SQL删除:支持标准 FROM table WHERE 语法。在主键模型上,删除性能与数据量成正比;在明细/聚合模型上,删除速度快但高频操作会影响查询性能 。
五、性能优化与高阶实践
1. 高并发点查
对于车联网、电商大屏等场景,要求4万QPS/s以上的并发点查能力 。
优化路径:Doris通过短路径优化,FE()节点接收请求后直接生成轻量化执行计划,绕过复杂的MPP查询生成流程,实现亚秒级响应 。
2. 异步物化视图(Async View)
对于复杂聚合查询或数仓分层场景,利用异步物化视图预计算结果,实现查询加速。
适用场景:包含多表Join、复杂聚合的计算密集型分析;加速数据湖(Hive、)查询 。
注意:异步物化视图存在数据延迟(分钟级),不适合需要1-5分钟内实时数据的场景 。
3. 冷热数据分层
通过Doris的冷热分层功能,将热数据(高频访问)存储在SSD上保证查询速度,冷数据(历史数据)自动迁移到HDD或对象存储(S3) 。
收益:岚图汽车实践显示,存储成本降至原有的1/3 。
4. 资源隔离与熔断
Group:利用资源组对不同业务进行CPU/内存的硬隔离,避免查询相互干扰 。
SQL熔断:设置运行时策略(如执行时间>2分钟自动熔断),或规划时阻止全表扫描等高代价查询,保障集群稳定性 。
六、行业实践案例验证
小米:基于Doris 3.0构建统一OLAP体系,日均查询量5000万次,管理PB级数据。利用Doris替换Trino,数据湖查询效率提升3-5倍 。
岚图汽车:每日处理百亿级车联网数据。通过Doris实现高并发点查(4万QPS/s),利用冷热分层降低60%存储成本,并使用Doris 实现自动化运维 。
七、总结与最佳实践路径
若要在生产环境中落地 Doris实时数据分析,请遵循以下“标准答案”路径:
1. 模型选型:凡涉及更新,一律采用主键模型,并开启默认的写时合并(MoW)。
2. 数据接入:优先采用 Load (Kafka) 或 Flink (CDC) 保证秒级延迟。
3. 更新逻辑:利用 语义 处理常规变更;遇到乱序数据时,必须配置 列;对于宽表,使用部分列更新优化效率。
4. 查询优化:针对点查配置短路径优化;针对复杂报表构建异步物化视图。
5. 运维保障:实施冷热分离控制成本;配置资源组和熔断策略保证集群稳定。