
别再被MySQL的并发瓶颈卡死了!每天上亿用户在线、每秒百万级写入,你的业务系统还能撑多久?这种分布式NoSQL数据库,专为这种场景而生,能让你轻松驾驭海量数据洪流。
到底强在哪
它最大的亮点就是去中心化架构,没有单点故障。集群里的每个节点都是对等的,谁也不用听谁的,任何一个节点挂掉,整个集群照常运转。这种设计让系统的可用性极高,特别适合那些需要7×24小时在线的互联网服务。
这种架构基于一致性哈希算法来分布数据。比如你有100个物理节点,它会把所有数据通过哈希计算,均匀打散到这100个节点上,并且自动保存多份副本。当你要扩容到200个节点时,只有极少一部分数据需要迁移,成本极低。
查询像用MySQL一样简单
传统观念里,NoSQL数据库查询都很复杂,但它内置了CQL查询语言,语法和MySQL几乎一样。你会写SELECT * FROM user WHERE age > 18,就能用它,学习成本几乎为零,开发人员上手特别快。
它支持二级索引,这是很多NoSQL数据库的短板。比如你要根据用户的城市字段来查人,可以直接在这个字段上建索引,查询速度飞快。而HBase这类数据库,没有这个功能,只能扫全表,非常痛苦。
数据模型灵活多变

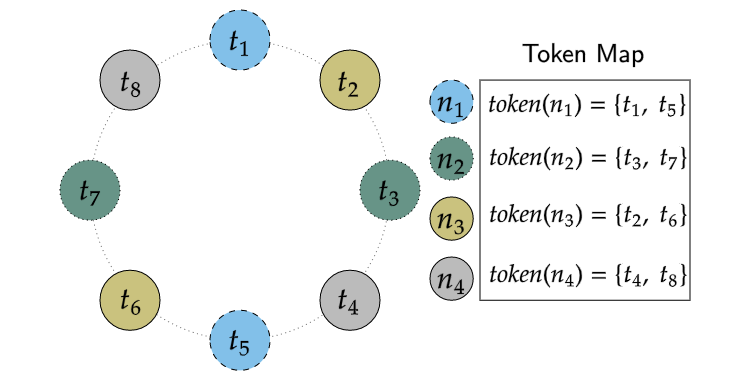
它的表结构很特别,支持静态字段和动态字段。静态字段就像SQL里的列,定义好就不能变;动态字段则非常灵活,字段名和值都由应用程序在写入时动态生成,特别适合存储属性不固定的数据,比如用户自定义标签。
# 通过官网下载下载最新的版本
wget https://dlcdn.apache.org/cassandra/4.1.1/apache-cassandra-4.1.1-bin.tar.gz
# 解压
tar -xvf apache-cassandra-4.1.1-bin.tar.gz
# 进入目录
cd apache-cassandra-4.1.1
# 启动,如果是root用户启动bin/cassandra -R
bin/cassandra
# 查看日志
tail -f logs/system.log
# 检查Cassandra的状态
bin/nodetool status行键就是主键,总是被索引。你可以用PRIMARY KEY关键字定义复合主键,比如(用户ID, 订单时间)。这样查询某个用户的所有订单,或者按时间范围筛选,效率都极高,不用像MySQL那样担心索引失效。

写入速度为什么这么快
# 同一个集群名称一样
cluster_name: 'Test Cluster'
# 种子地址,配置多个示例,用逗号隔开
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "192.168.2.100,192.168.2.101"
listen_address: 192.168.2.100
rpc_address: 192.168.2.100
# 下面文件路径按需修改,建议多个盘分开提高读写性能
# 数据文件(如sstable)所在的一个或多个目录,默认$CASSANDRA_HOME/data/data
data_file_directories: /data1/cassandra/data
# commitlog文件所在的目录
commitlog_directory: /data2/cassandra/commitlog
# 保存缓存的目录
saved_caches_directory: /data3/cassandra/saved_caches
# hints所在的目录
hints_directory: /data4/cassandra/hints# 需要先杀死原来的cassandra进程,也可以自己准备脚本
ps -ef | grep cassandra
# 检查Cassandra的状态
bin/nodetool status
# 查询关于令牌环的信息
bin/nodetool ring它的写入速度能达到每秒数十万甚至上百万,秘诀在于它的存储引擎。数据写入时,先写内存缓冲区和预写日志,内存满了再批量刷到磁盘,形成不可变的数据文件。这个过程是顺序IO,比MySQL的随机IO快好几个数量级。
它基于分阶段事件驱动架构实现分布式存储,每个节点都有三个核心组件协同工作。特别是日志结构化合并树引擎,保证了写入吞吐量的同时,还能维持稳定的读取性能,让你在数据爆炸式增长时也能从容应对。

集群管理靠协议
它的去中心化特性依赖于协议和反熵机制。协议让每个节点都知道集群里有哪些其他节点,状态是活的还是死的。反熵机制则负责在后台比对数据,确保不同节点上的数据最终达成一致,这就是最终一致性。
但这种机制也有代价,集群规模不能太大,一般建议几十到上百个节点。节点太多,网络通讯会变得非常密集,维护难度直线上升。所以它适合数据量大但集群规模可控的场景,比如物联网数据采集、用户行为日志。
什么场景最适合用
# CQL Shell 简称cqlsh,是一个可以和Cassandra数据库通信的客户端,使用这个cqlsh客户端可以执行Cassandra查询语言(CQL)。指定IP和端口连接cql
./bin/cqlsh 192.168.2.100 9042
describe cluster;
describe keyspaces;
describe tables;如果你的业务需要每秒处理海量写入,又要支持灵活的SQL查询,还要保证全年无故障运行,那它就是MySQL的绝佳替代品。比如大型电商的订单系统、社交App的消息记录、游戏行业的玩家行为日志,都是它的用武之地。
但它不适合随机性极强的点查,比如要根据好几个字段的复杂组合来查,或者对事务强一致性有严格要求的金融交易。这种场景还是得交给关系数据库,各司其职才是最佳实践。
# 将输出内容捕获到名为outputfile的文件
capture 'outputfile';
# 创建键空间
CREATE KEYSPACE school WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};
# 查看捕获内容
cat outputfile你看完这篇文章,觉得这种去中心化的数据库设计,未来会不会彻底取代传统的关系型数据库?欢迎在评论区分享你的看法,觉得文章有用的话,别忘了点赞转发!
# 查看键空间
DESCRIBE school;
# 使用键空间
use school;
# 修改键空间
ALTER KEYSPACE school WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 1};
DESCRIBE school;
# 删除键空间
DROP KEYSPACE school;







