还在为部署大模型的繁琐流程头疼?刚开源的全球最强Qwen3.5-397B模型,现在用阿里云函数计算(FC)就能一键搞定,这可能是你距离顶级AI能力最近的一次。
模型突破
这次阿里开源的Qwen3.5-397B-A17B模型在技术架构上实现了重大革新。它采用了混合专家架构,总参数量达到惊人的3970亿,但每次推理仅激活170亿参数,这种设计在保持强大性能的同时大幅降低了计算成本。
从实际测试数据来看,新模型在数学推理、代码生成和多语言理解等多个基准测试中均刷新了纪录。相比前代版本,它的推理速度提升了约30%,特别在处理复杂逻辑问题时表现更为出色。
传统部署痛点
过去开发者部署大模型往往面临硬件门槛过高的问题。想要运行397B级别的模型,通常需要配置多块A100或H800显卡,单是硬件采购成本就可能高达数十万元,个人开发者根本负担不起。
环境配置更是让人望而却步。从驱动安装到CUDA版本匹配,再到各种依赖库的兼容性调试,稍有差错就要重头再来。有开发者统计过,第一次部署大模型平均要花费3到5天时间。
函数计算方案

阿里云函数计算FC这次同步接入了Qwen3.5全系列模型,提供了企业级的部署方案。它基于最新的GPU架构,你完全不用关心底层基础设施怎么搭建,服务器怎么扩容,只要专注于模型本身的应用调试就行。
FC平台最大的亮点在于按量付费模式。对于个人开发者来说,平时测试可能只需要几块钱,比起自建服务器动辄数万的投入,门槛直接降到了地板价。而且平台自动处理负载均衡和弹性伸缩。
一键部署实战
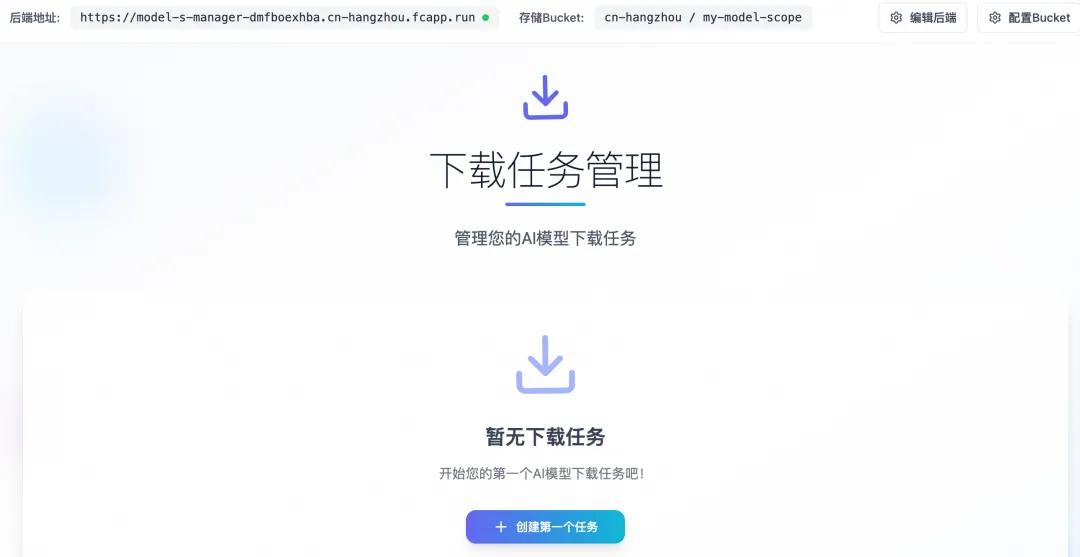
第一步先准备OSS存储空间,然后用平台提供的白屏化工具部署一个下载器。打开工具界面后,在后端配置里填入模型ID“Qwen/Qwen3.5-397B-A17B”,指定好OSS目录,点击开始下载就行了。模型文件很大,得耐心等上一阵子。

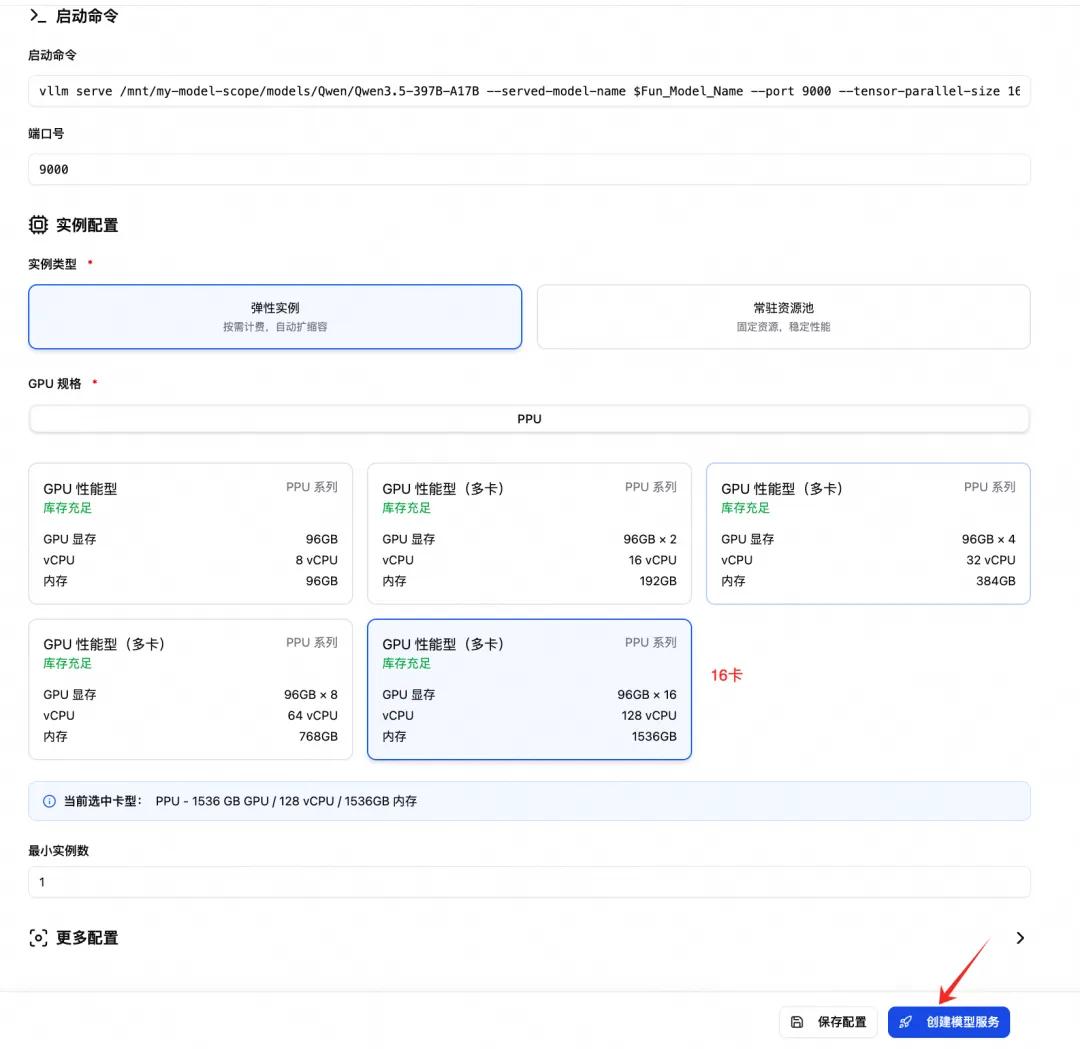
下载完成后进入函数计算的控制台,找到自定义部署选项。选择官方提供的PyTorch镜像,计算资源选配备GPU的实例类型。最关键的是启动命令,要按照官方文档填写正确的参数,配置好后点击部署,等状态变成运行中就算成功了。
模型市场延伸

函数计算平台内置的模型市场还在持续扩充Qwen3.5系列的其他变体。除了这次的主角397B版本,还有适合轻量级应用的7B和14B版本,以及专门针对代码任务优化的Coder系列,都能一键部署。
每个模型在市场上都配有详细的部署文档和示例代码。比如7B版本甚至能在普通的消费级显卡上运行,而72B版本则适合企业级应用。开发者可以根据自己的实际需求选择合适的模型规模。
总结思考
vllm serve /mnt/my-model-scope/models/Qwen/Qwen3.5-397B-A17B --served-model-name Qwen/Qwen3.5-397B-A17B --port 9000 --trust-remote-code --gpu-memory-utilization 0.9 --max-model-len 262144 --tensor-parallel-size 16 --enable-auto-tool-choice --tool-call-parser qwen3_coder --reasoning-parser qwen3 函数计算FC这种Serverless模式确实改变了大模型的落地方式。它让个人开发者花几块钱就能玩转顶级模型,企业也能省去运维团队的成本,快速把AI能力集成到产品里。从下载模型到提供服务,全程不用接触复杂的底层配置。
不知道你现在手头有没有正在构思的AI应用?如果部署门槛不再是问题,你最想用这个大模型来做什么?欢迎在评论区分享你的想法,觉得有用的话记得点赞转发让更多开发者看到。