分布式数据库的全球部署能力一直是技术圈的热门话题,今天要聊的这款DB产品,不仅能把节点铺到全球各地,还完整支持ACID事务,这种听起来有点矛盾的特性,正是它最大的技术亮点。

架构设计的两层逻辑
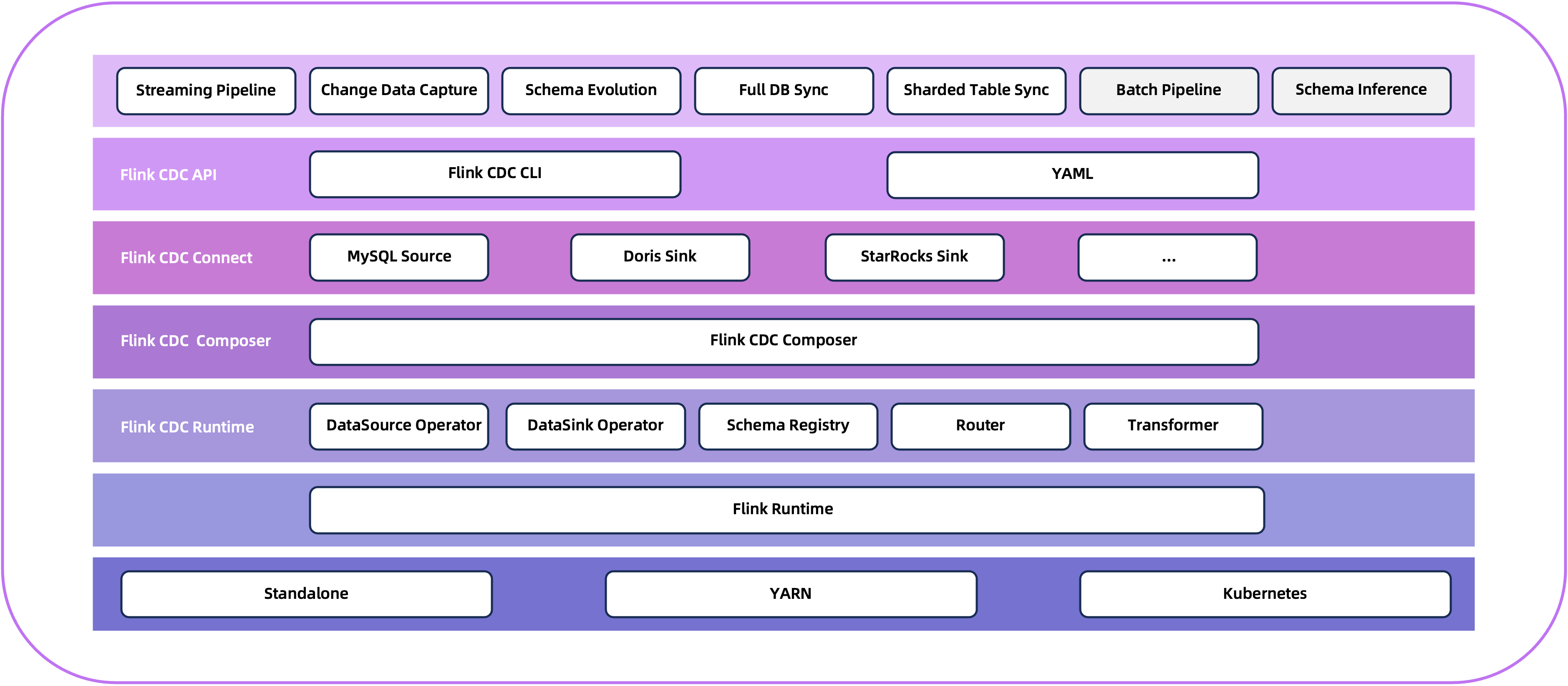
从逻辑架构上看,DB采用了查询层和存储层的两层设计。查询层负责处理SQL和文档接口的请求解析,存储层则负责实际的数据持久化。这种分离让系统能够灵活应对不同类型的负载需求。
不过这个两层架构仅仅是逻辑上的概念,在实际部署时,两层都运行在同一个DB进程中。这种设计既保持了架构的清晰性,又避免了分布式系统常见的网络开销,算是在理论和实践之间找到了平衡点。
双API接口的查询层实现
查询层最特别的地方在于它同时支持SQL和CQL两种API。CQL是一种兼容文档数据库的方言语法,对应着底层的文档存储模型,让习惯文档数据库的开发人员能无缝迁移。

SQL接口则是基于流行的PG语法引擎改造而来。官方声称这样可以更方便地跟随PG的新特性,但实际效果如何,还需要经过大规模生产环境的检验。毕竟魔改开源代码这种事,往往没有说起来那么美好。
数据分片与Raft复制组
每个Tablet对应一个Raft Group,分布在三个不同节点上,这是保证高可用的核心机制。通过这种方式,即使某个节点宕机,数据服务也不会中断,Raft协议会自动选出新的Leader继续处理请求。
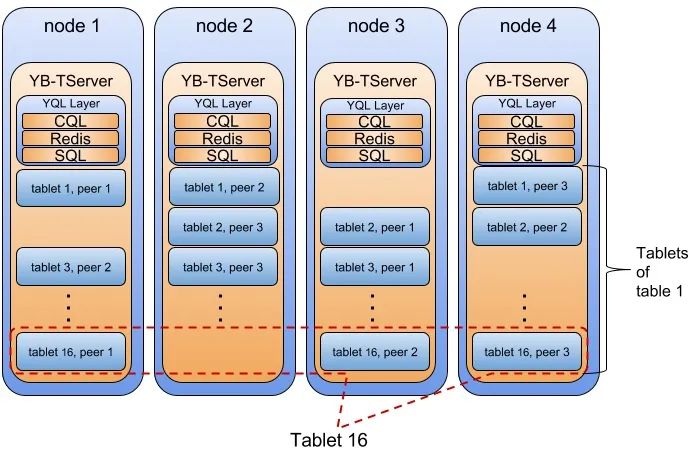
这种设计其实是吸收了HBase/Bigtable的精髓,TiDB和国外的同类产品也采用了几乎一模一样的做法。每张表被切分成多个Tablet,作为数据分布的最小单元,通过在不同节点间搬运Tablet,实现几乎无上限的水平扩展。
独特的分区策略选择
DB采用了哈希和范围结合的分区方式,这一点与只支持范围分区的TiDB和CockroachDB不同。哈希分区将key映射到2字节的空间中,再划分成多个范围,每个范围落在具体的Tablet上。
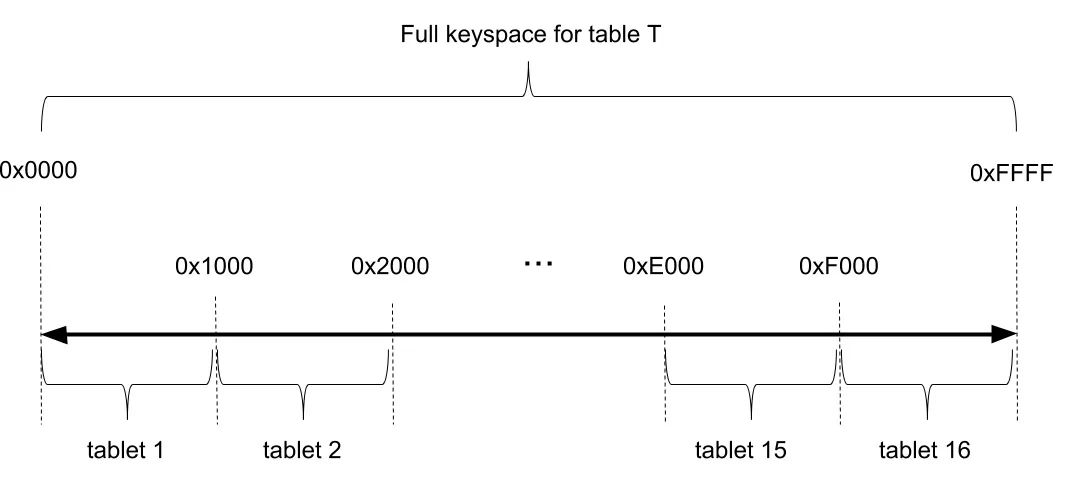
理论上最多可以有64K个Tablet,对绝大多数业务场景都足够了。哈希分区的最大好处是插入数据时不会出现热点问题,但坏处是小范围的范围扫描性能会受影响,需要根据实际业务场景权衡选择。
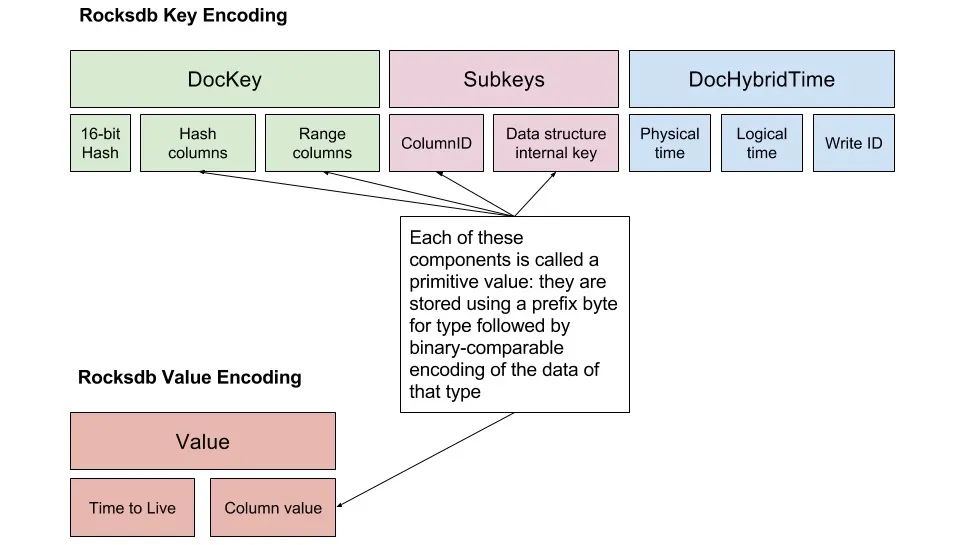
本地存储与数据编码
每个节点上的本地存储被称为DocDB,底层使用RocksDB作为存储引擎。这一层需要将关系型数据和文档数据都编码为key-value格式,保存到RocksDB中。编码方式有很多精巧的设计,比如为兼容文档模型而做的特殊处理。
如果抛开文档模型不谈,这种key-value的设计思路和TiDB很像,每个单元格对应一个key-value。通过这种统一编码,上层可以灵活支持不同的数据模型,而底层存储引擎只需要关心键值对的读写。
分布式事务的时间戳选型
时间戳是分布式事务的关键选型之一,DB采用了HLC混合逻辑时钟。它将时间戳分成物理和逻辑两部分,物理部分对应UNIX毫秒时间,逻辑部分处理同一毫秒内的事件顺序。当发生RPC通信时,逻辑时钟会自增,确保操作之间形成偏序关系。
另一种方案是TiDB采用的TSO中心授时节点,实现简单但增加了网络RPC,且TSO一旦不可用就会影响整个集群。HLC的缺点是不能提供严格意义上的外部一致性,只能保证相关事务之间的顺序关系,这是分布式系统理论中著名的CAP权衡。
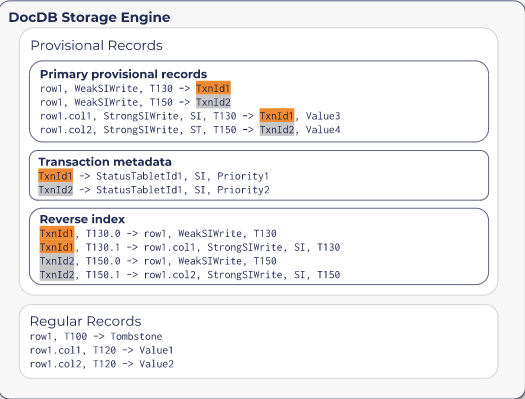
事务提交过程中,系统会在DocDB存储中写入临时记录,包括事务元数据、写入意向和事务状态三种类型。事务状态保存在专门的表中,有Pending、Committed或Aborted三种可能。当状态切换到Committed的那一刻,事务才算真正成功提交。
最后问大家一个问题:如果你的业务需要全球部署,你会选择HLC这种去中心化的时间戳方案,还是TSO这种中心化的方案?欢迎在评论区分享你的观点,点赞和转发能让更多人参与讨论。