从清华实验室走出的IoTDB,凭什么成为国内高校首个进入Apache孵化的项目?这个2014年启动的自研时间序列数据库,正在工业物联网领域掀起一场技术变革。
七年磨一剑的诞生之路
2014年,清华大学软件学院的科研团队意识到工业物联网领域对时序数据管理的迫切需求,正式启动了IoTDB项目。当时团队成员只有寥寥数人,在实验室里默默耕耘着底层文件存储格式,这成为后来整个项目的技术基石。
2016年3月,一位新成员加入清华软件学院存储组,那时团队正专注于时间序列数据的文件格式研发。每两周一个冲刺的开发节奏,让大家在代码世界里挥洒着汗水,不断推进着与Hadoop、Spark、Hive、Avro等开源生态的对接工作。
从文件层到数据库的蜕变
2017年4月1日凌晨5点,团队拍下了一张值得纪念的照片,那天他们发布了第一个稳定版的文件层。但团队很快意识到,仅有文件层远远不能满足工业物联网场景下的复杂需求,于是决定基于文件层开发完整的时序数据库IoTDB。
这次蜕变意味着巨大的技术跨越。团队需要从零开始构建SQL解析引擎、执行计划模块,还要开发写入模块、查询模块和写前日志等核心功能。每个模块都是一道技术难题,团队成员在不断地写bug、改bug中积累着宝贵经验。
在推翻重建中持续进化
软件开发没有一蹴而就的成功,IoTDB的发展历程充满了重构的阵痛。2017年底,团队进行了一次大规模的读写流程重构,试图设计一套清晰的读流程框架,却发现重构后性能不升反降。
面对挫折,团队没有气馁。2018年底,他们再次发起读流程重构,这次从文件层到顶层的IoTDB都进行了大改版。正是这种不断推翻重建的执着精神,让IoTDB的性能最终实现质的飞跃。
国际权威认证的性能优势
基准测试表明,IoTDB的读写性能全面优于现有的InfluxDB、TimescaleDB、OpenTSDB以及GE的工业大数据平台。更令人振奋的是,中国软件评测中心和中国人民大学的联合测试证实,IoTDB的各项性能指标都明显优于当今国际最优的时序数据库系统。
目前IoTDB核心模块有效代码已达7万余行,通过DSL语言生成代码6万余行。代码提交更新次数超过1300次,用户反馈、建议与回复超过200次,社区的活跃度持续攀升。
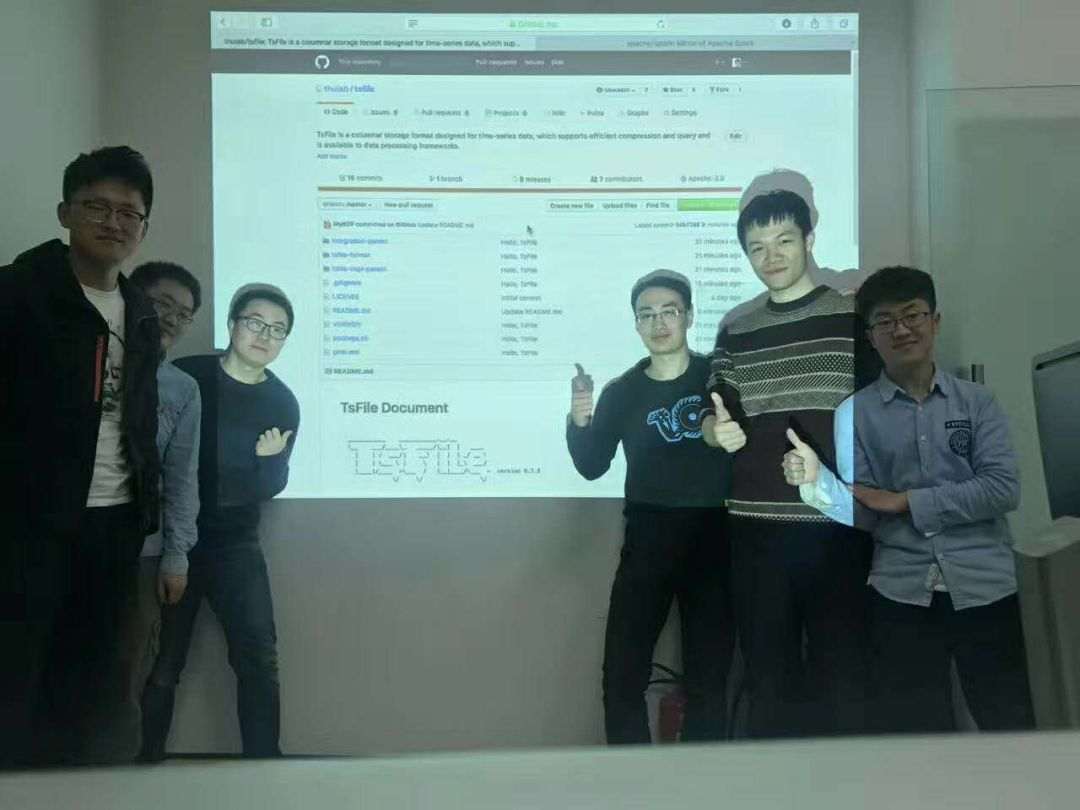
高校首个闯入Apache孵化器
2018年,IoTDB团队开始积极准备进入Apache孵化器。他们撰写提案,联系导师,争取投票,最终在11月18日迎来历史性时刻——IoTDB正式成为Apache孵化器项目,这是我国高校目前唯一一个进入Apache孵化器的项目。
孵化器主席、国际著名大数据公司Cloudera副总裁Joe Witt,PLC4X项目负责人Christofer Dutz,华为开源中心负责人姜宁都成为本项目的指导者。投票中IoTDB获得10票赞成,充分证明了国际开源社区对这个来自中国高校项目的认可。
开源生态的持续完善
进入Apache孵化器后,团队立即投入网站建设和文档翻译工作,为全球开发者提供更好的使用体验。目前IoTDB已完成与Hadoop、Spark等开源大数据生态的集成,开发了JDBC形式的编程SDK、导入导出工具、可视化工具、命令行交互工具、数据回传工具等多项辅助工具。
社区采用邮件列表进行日常沟通,任何人都可以通过发送邮件订阅IoTDB邮件列表,加入开发者社区。贡献代码的开发者还有机会成为Apache Committer,获得那个令人向往的Apache图标。
从2014年实验室的一个想法,到今天成为Apache孵化器项目,IoTDB用七年时间证明了国产基础软件的实力。你觉得中国高校的开源项目,未来能在国际舞台上占据怎样的地位?欢迎点赞、分享本文,在评论区留下你的看法!