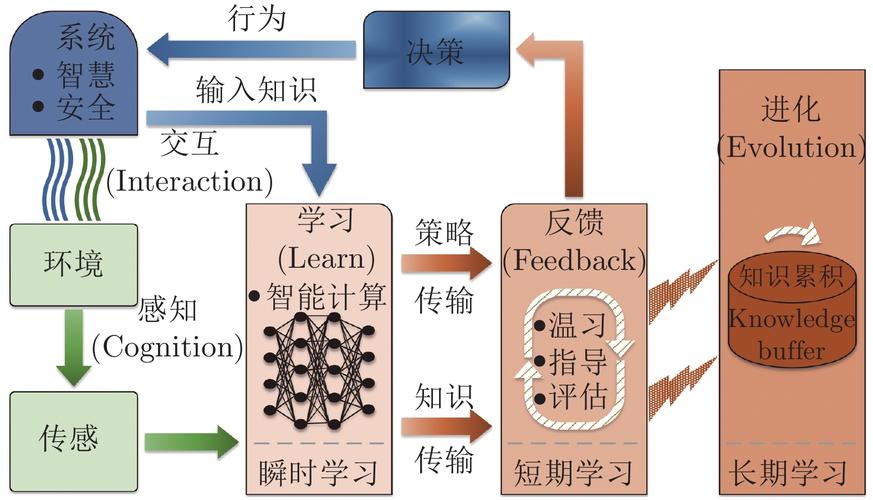
我们花了三年时间,总算把公司那套臃肿的离线批处理加实时流计算的双修架构,彻底改造成了基于 Flink 的纯流式Kappa架构。改造完成后,服务器成本降了30%,数据对账的时间从每周一次变成了随时可查,业务方再也没拿着两张报表来质问我们该信哪个数。
资源复用:让每一核CPU都转起来
Kappa架构带来的第一个直观改变就是集群资源的利用率。以前我们得维护两套独立的Hadoop集群,一套跑夜间的T+1离线任务,一套跑白天的实时任务。凌晨两点,实时集群的机器空转,离线集群却在疯狂抢资源,这种割裂直接导致计算资源的双重浪费。
改造后,我们直接把所有数据源统一接入Kafka,用同一套Flink集群处理所有任务。Flink优秀的流批一体能力,让我们能在一个作业里同时处理实时数据和补录的历史数据。白天处理实时订单流,凌晨通过修改作业的启动时间戳,同一个作业立刻就能回刷过去24小时的数据进行重跑。
这套架构跑下来,集群的平均负载从以前的忽高忽低变得非常平稳。以前高峰期需要准备30台机器应对实时流量,现在20台机器就能搞定,因为批处理任务不再需要独立维护一套物理资源,彻底打破了“白天流忙、晚上批忙”的死循环。
代码统一:告别两套逻辑的噩梦
代码维护成本的降低才是最让开发团队舒心的地方。以前我们维护一个订单GMV指标,实时任务用Flink写一套逻辑,离线报表用Spark SQL再写一套。业务逻辑稍微调整,比如修改优惠券分摊规则,两个项目就要同时改代码、同时发布,还经常因为UDF函数行为不一致导致数据对不上。
现在所有逻辑都统一用Flink SQL实现。订单流入Kafka后,我们会先做简单的ETL清洗,然后直接关联存储在HBase中的维度表。Flink SQL强大的维表关联功能,让我们能用Join语法实时补齐商品类目名称,而且支持异步IO,不会因为查数据库而阻塞整个流。
这套代码既跑在实时流上,也能跑在批处理上。每个月做数据质量稽核时,我们只需要把作业的消费位点调整到月初,Flink就会自动以批模式高效地处理这一个月的历史数据,产出的结果和实时作业完全一致,彻底根除了数据不一致的顽疾。
维表关联:实时流中的静态数据补全
在电商场景中,业务逻辑高度依赖维度信息。订单流里只有商品ID,我们需要实时把它翻译成类目名称、品牌、店铺等级等信息,才能写出易于理解的分析报表。在Kappa架构下,这个维表关联环节必须做到低延迟和高可用。
我们选择用HBase作为维表存储,因为它既能支撑高并发的点查,又有不错的横向扩展能力。Flink SQL通过创建临时表关联HBase的方式,让维表变得像本地表一样易用。我们在DDL语句中指定了缓存策略,将热点数据缓存在内存中,既减轻了HBase的压力,又大幅提升了关联速度。
实际生产中还遇到了维度数据变化的问题,比如商品换类目。我们用Flink的时态表功能来解决,记录每个商品的类目变更历史。当订单流到达时,能根据订单的时间戳关联到当时正确的类目,保证历史重跑和实时计算的结果完全对齐,不会出现张冠李戴的统计错误。
迟到数据处理:窗口计算不再丢数据
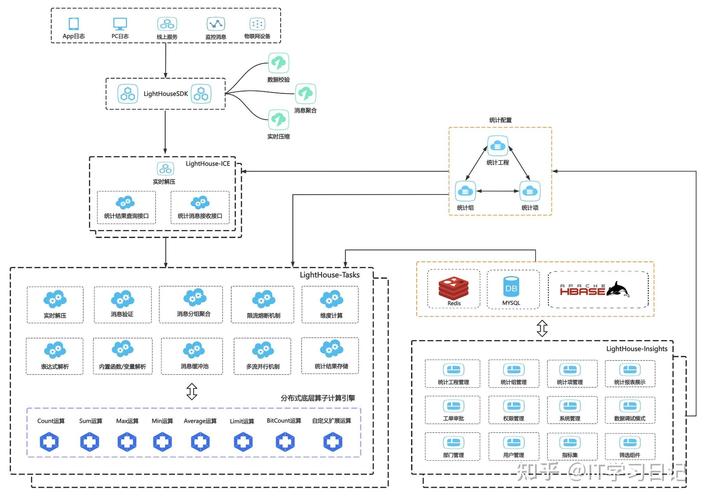
实时计算中最让人头疼的就是数据迟到问题。用户在下单后可能修改收货地址,或者因为网络波动导致日志上报延迟,这些数据如果处理不当,就会在最终统计中丢失,导致第二天看板和前一天对不上。
Flink提供了完善的迟到数据处理机制。我们在订单统计作业中定义了滚动窗口,并设置了允许的迟到时间和侧输出流。迟到的数据不会被直接丢弃,而是被发送到一个专门的流里,由另一个作业负责更新已关闭窗口的结果。
这样设计之后,哪怕数据迟到一两个小时,最终的聚合结果依然能自动修正。业务方发现昨天的销售额数字变了,我们解释是修正了延迟日志,他们表示理解,因为总比直接丢掉数据要好。这套机制确保了数据的最终一致性,完美支撑了财务对账这种对准确性要求极高的场景。
检查点配置:流作业的保命符
Kappa架构下,流作业7×24小时不间断运行,出问题时的恢复能力就至关重要。Flink的检查点机制是我们最依赖的保命符,它通过定期保存状态快照,让作业在失败后能恢复到最近一次成功状态,实现精确一次处理语义。
我们在生产中调整了检查点配置,设置间隔为1分钟,并启用了增量检查点。因为状态量很大,每次全量保存太耗资源,增量模式只保存变化部分,对性能影响小得多。同时配置了最大并发检查点数为1,防止多个检查点同时进行导致负载飙升。
有一次物理机宕机,作业自动重启后从检查点恢复,我们盯着监控看,数据延迟从几分钟慢慢追平,最终一条数据都没丢。这种容错能力给了我们极大的安全感,以前用离线批处理重跑一天数据要两小时,现在流作业恢复只需要几十秒。
监控告警:第一时间发现异常
架构再健壮,也离不开监控的眼睛。我们基于Flink的指标系统搭建了完整的监控体系。重点关注两个核心指标:数据延迟和反压情况。数据延迟一旦超过阈值,说明消费能力跟不上生产速度,需要扩容或者优化算子性能。
反压监控帮我们定位了多次性能瓶颈。有一次我们发现作业越来越慢,点开监控看到某个算子反压很高,检查代码发现是维表查询没加异步IO,改成异步模式后,吞吐量直接翻倍。现在我们把所有关键作业的监控指标都接入了告警平台。
我们还对作业的Failover次数做了统计。某个作业频繁重启,虽然能恢复,但说明有问题,最终排查出是某个业务数据格式突变导致的解析异常。及时发现并修复这些问题,让我们的Kappa架构运行得越来越稳定。
-- 启动Flink SQL Client,并指定初始配置
-- 流模式执行(默认)
SET 'execution.runtime-mode' = 'streaming';
-- 或者,批模式执行(用于历史数据补算或测试)
SET 'execution.runtime-mode' = 'batch';
-- 创建源表:订单事实流(假设数据来自Kafka)
CREATE TABLE order_events (
order_id STRING,
product_id BIGINT,
amount DECIMAL(10, 2),
event_time TIMESTAMP(3),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'orders',
'properties.bootstrap.servers' = 'kafka-broker:9092',
'properties.group.id' = 'f你所在的公司是否也正在经历数据架构转型的阵痛?对于从离线批处理转向实时流处理,你最大的顾虑是什么?欢迎在评论区分享你的经历和困惑,点赞转发让更多数据人看到这篇实战分享。