数据量达到PB级别时,Hudi流式入湖作业如果还像小规模数据那样配置,反压和资源成本飙升几乎是必然的。这个痛点正是Hudi 1.1版本重点解决的,我们通过几个关键优化,让Flink流式写入性能实现了数倍提升。
序列化与反序列化开销的精准打击
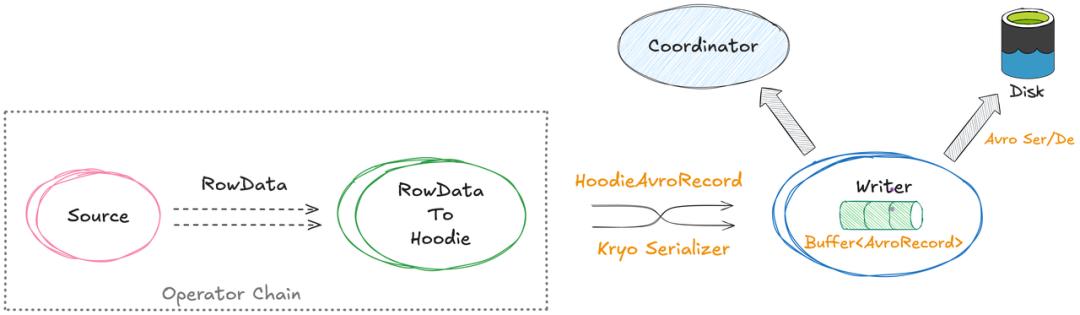
在Hudi 1.1版本之前,Flink的Internal数据类型要写入Hudi,必须先转换为Avro对象。这个转换过程看似简单,但在PB级数据规模下,CPU资源就被大量消耗在这上面。特别是在算子没有被Chain在一起的情况下,数据还得序列化成字节流通过网络传输,导致序列化操作长期占据CPU开销的前几位。
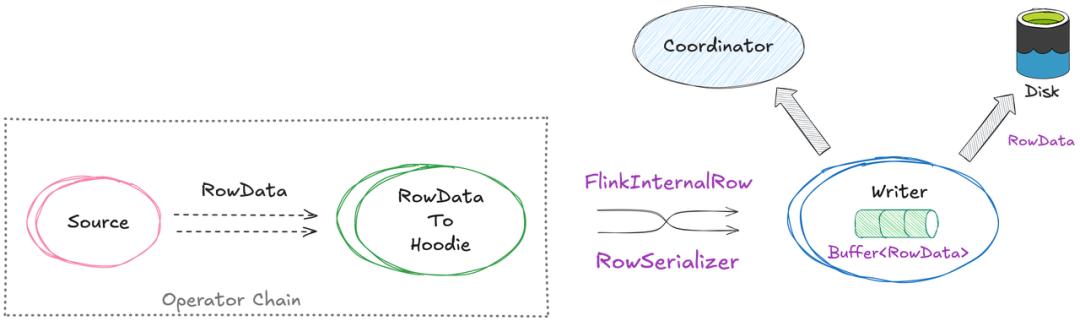
Flink对基础类型有内置的高效序列化器,但对于GenericRecord这类通用类型,它会回退到性能较差的Kryo序列化器。Hudi 1.1版本通过RFC-84和RFC-87两个重要改进,定制了Flink原生数据结构并配套了专用序列化器,让数据在整个写入链路中不再进行冗余的Avro转换,吞吐量因此平均提升了约25%。

日志文件写入中的字节拷贝消除
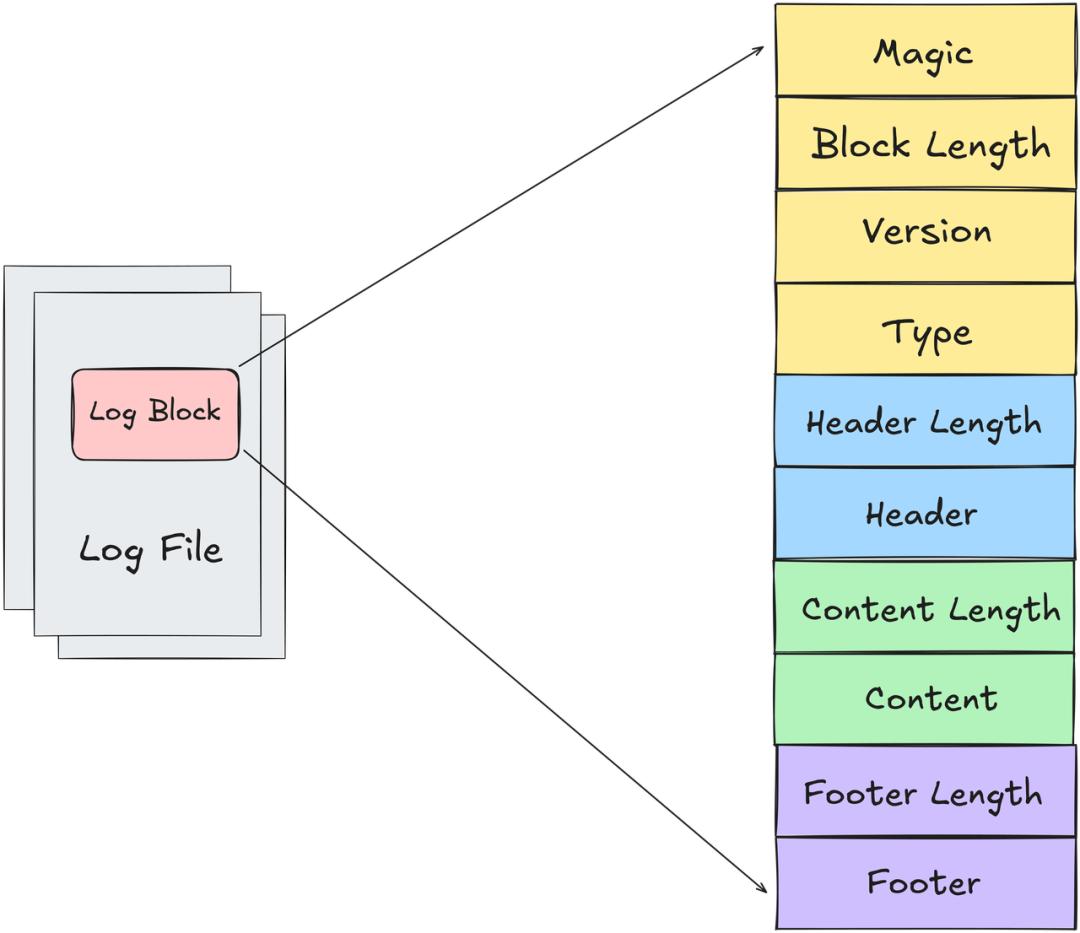
MOR表的日志文件写入机制,在Hudi 1.1版本前也存在一个容易被忽视的性能瓶颈。每条数据在通过Avro序列化写入DataOutputStream后,需要调用toByteArray()方法获取字节数组,这个方法底层会创建新的字节数组并将数据拷贝进去。在大流量场景下,这种按条进行的字节拷贝会产生海量临时对象,给GC带来巨大压力。
Hudi 1.1版本对此做了细致优化,利用OutputStream自身提供的方法,直接将底层的字节数组写入外层Block输出流。这个改动虽然看起来不大,但却消除了记录级别的字节拷贝开销,有效缓解了高吞吐写入时的GC压力,让作业运行更加稳定。
性能基准测试环境与配置透明化

为了验证优化效果,我们基于阿里云EMR集群搭建了测试环境。集群配置采用3台ecs.g7.4xlarge实例作为核心节点,每台配备16核CPU、64GB内存和3块100GB SSD云盘,主节点则使用ecs.g7.2xlarge。这样的配置在生产环境中非常典型,测试结果具备实际参考价值。
测试数据总量达到5亿条,主键范围从0到1亿,使用Flink的DataGenSource模拟真实工作负载。我们禁用了compaction以避免它对写入性能造成干扰,同时除了默认的TPC-DS表类型,还增加了三种包含更多字符串字段的表结构,更贴近生产环境中的实际表模式。
与Iceberg的基准测试对比结果
这次基准测试选取了Hudi 1.1、Hudi 1.0以及Iceberg 1.0.1进行对比,测试场景是最常见的MOR表配合upsert操作和bucket索引。此前Iceberg宣称其入湖性能相对Hudi有数倍提升,这也是他们向用户推广的重要卖点,所以我们特别关注这个对比。
测试结果显示,Hudi 1.1在Flink写入器性能方面的优化带来了数倍的吞吐量提升。这意味着在同样的资源消耗下,Hudi 1.1能够处理更多的流入数据,或者反过来说,处理同样的数据量可以占用更少的计算资源,直接降低了流式入湖作业的资源成本。
优化成果的透明性与兼容性优势
这些性能增强不是通过改变用户使用方式换来的,而是完全透明的优化。用户从早期Hudi版本升级到1.1版本时,现有的Flink流式入湖作业不需要做任何代码修改,也不需要调整运维配置,就能直接享受到性能提升。
这种向后兼容的设计极大降低了用户的升级成本。在实际生产环境中,数据团队往往因为担心影响线上作业稳定性,而迟迟不敢升级版本。Hudi 1.1通过保持API和接口不变,只重构内部实现的方式,让版本升级变得风险更低。

流式入湖优化的实际价值展望
PB级数据规模下的流式入湖,每一个微小的性能优化都会被放大成可观的实际收益。Hudi 1.1版本在序列化开销、字节拷贝这些细节上的打磨,最终体现在作业反压的减轻和资源使用率的下降上。
对于正在使用Flink+Hudi构建实时数据湖的团队来说,这意味着可以用更少的服务器处理更多的实时数据,或者在同等资源下获得更低的端到端延迟。那么你在实际生产环境中,是否也遇到过流式入湖作业的反压问题?欢迎在评论区分享你的优化经验,点赞转发让更多人看到这些实用的性能调优方向。