
开发的爬虫工具能帮助我们高效地收集网络资料,这种程序在数据处理和收集环节中起到了至关重要的作用。接下来,我会逐一为大家详细解释。
引用资源模块
在编写爬虫的源代码过程中,引用资源模块显得尤为重要。这和盖房子前需要准备材料的情况相似,编写爬虫程序之前,也必须引入相应的模块。比如,模块是用来执行HTTP请求的,而模块则是用来分析HTML页面的。引入这些模块之后,我们为后续的数据抓取打下了坚实的基础,因此,我们能够更加顺畅地从网站中提取所需的信息。
分析页面结构
为了搜集信息,我们得先弄清楚网页上数据的展示形式。打开网页,按F12键进入开发者模式,仔细观察。通常,数据是通过集合的循环来展示的。一旦我们熟悉了页面元素的规律,就能准确提取所需数据,比如招聘网站的职位信息和薪资情况。这一环节是数据采集中的关键步骤。
获取列表页面内容
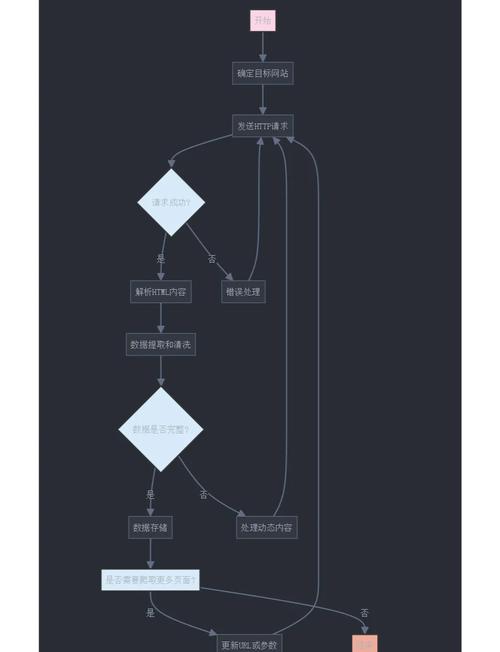
我们需要通过反复操作,逐个提取列表中各页面的详细信息。必须设定循环的规则,然后依次访问每一页。在循环中,对当前页面的内容进行分析,并依据这些信息找到下一页的链接,然后继续访问。这一过程就像攀登楼梯,一级级往上,逐页搜集数据,逐步扩大数据搜集的范围。
跳转详细信息页面
获取列表页面后,还需进入职业详情页面。这一过程中,同样要注意页面的跳转和信息解析。以招聘网站为例,用户一般会点击职位列表中的链接,查看具体职位要求。编写代码时,要实现这种跳转功能,并准确解析详细页面的信息,以便丰富数据资料。
数据写入Excel
所收集的数据资料可导入到Excel中。利用等工具,操作过程非常简单。对数据进行整理后导入Excel,便于后续的查阅和分析。比如,把搜集到的招聘信息整理成表格,这样数据就能清晰可见,从而提高数据处理的速度。
在使用这段代码时,大家是否遇到了什么困难?若有的话,欢迎点赞并转发本篇文章,同时,还请在评论区分享您的宝贵看法。






