
生态系统是以大数据处理平台为核心构建的,由此形成了一个技术集合。这个集合能够满足数据处理各个阶段的需求。下面,我将逐一介绍这个系统中包含的几种重要的技术。
数据采集
数据采集在大数据处理流程中扮演着核心角色,其重要性不言而喻。诸如Flume、、等工具,它们能够高效地搜集日志文件,确保海量的日志数据得以有序汇集。除此之外,Sqoop和Datax等工具则专注于在数据库与平台之间,实现结构化数据的迁移任务。一些企业利用Sqoop这一工具,将商业数据库中的数据导入分析平台,从而有助于公司更透彻地洞察消费者的购物倾向。
收集到的资料必须得到妥善保管,存放地点的选择同样至关重要。HDFS在处理海量数据上表现优异,并且具备出色的错误容忍存储能力。Kafka则负责消息队列的任务,具备高效的数据处理性能。在社交网络平台上,Kafka被用来存储用户行为数据,这有助于保障数据的实时性和稳定性,同时也满足了后续业务分析的需求。
资源管理
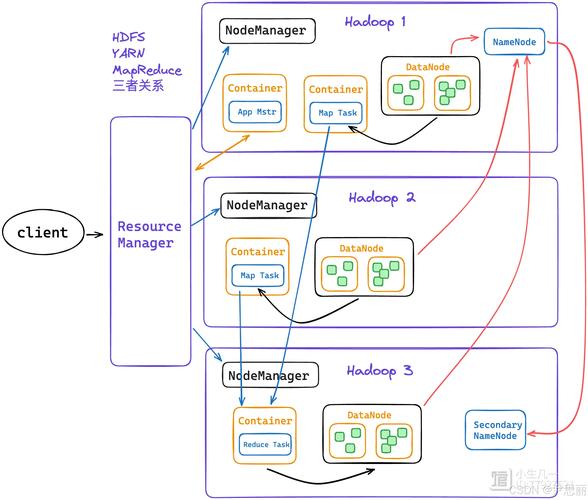
资源管理对于分布式系统来说至关重要。YARN系统承担着对集群内资源进行统筹规划和合理分配的重任,有效解决了资源竞争的难题。此外,平台还能实现资源的自动部署与扩展,显著增强了系统的稳定性。特别是在电商促销活动的高峰时段,运用YARN来管理资源、处理订单,能够确保交易系统的稳定运作。
数据计算
数据处理流程主要分为两个阶段:离线和实时。对于那些数据量庞大但时效性要求不高的任务,技术无疑是一个不错的选择。而在速度上,Spark技术则表现得更为出色。至于实时计算领域,Flink技术能够实现低延迟且高并发的流式数据处理。金融机构运用Flink技术对交易行为实施实时监督,以此确保能够快速识别并有效遏制潜在的风险。
数据分析
数据挖掘展示了数据内含的巨大潜力。在Hive这样的平台上,用户能够通过执行SQL语句来简化数据分析流程。而且,的分析系统以其快速响应著称,正因如此,它在众多互联网企业中得到了广泛的应用,用于分析用户访问情况。
在实际操作过程中,多数人感到生态系统中的某些技术框架学习起来较为困难。在此,我们诚挚邀请大家积极在评论区留言、点赞,并且将这篇文章分享出去。







