大模型研发与程序员之间的交集持续引发热议。华为云PaaS的大模型在编程研发方面有何表现?它是否有可能替代程序员?接下来,我们将深入探讨这个问题。
开源模型局限
在与产品线代码专家的交流中,我们发现开源的大规模语言模型存在缺陷。由于产业数据并未用于训练,该模型在研发阶段几乎派不上用场。信息通信技术的专业知识错综复杂,开源模型缺乏对领域知识的系统学习和系统设计的深入理解。这就像一个未经专业训练的初学者,面对复杂的任务时显得力不从心。
华为代码特征
华为的嵌入式系统主要采用C/C++语言进行编程。这种编程语言有其独特性,比如头文件机制使得类型和函数逻辑得以分离,从而拓展了状态空间。这种特点与许多开源项目所熟悉的代码环境存在显著差异,使得开源项目在处理这类代码的研发工作时面临较大挑战。然而,华为正是基于这种代码体系,致力于开展高效的研究与开发工作。
团队规范制定

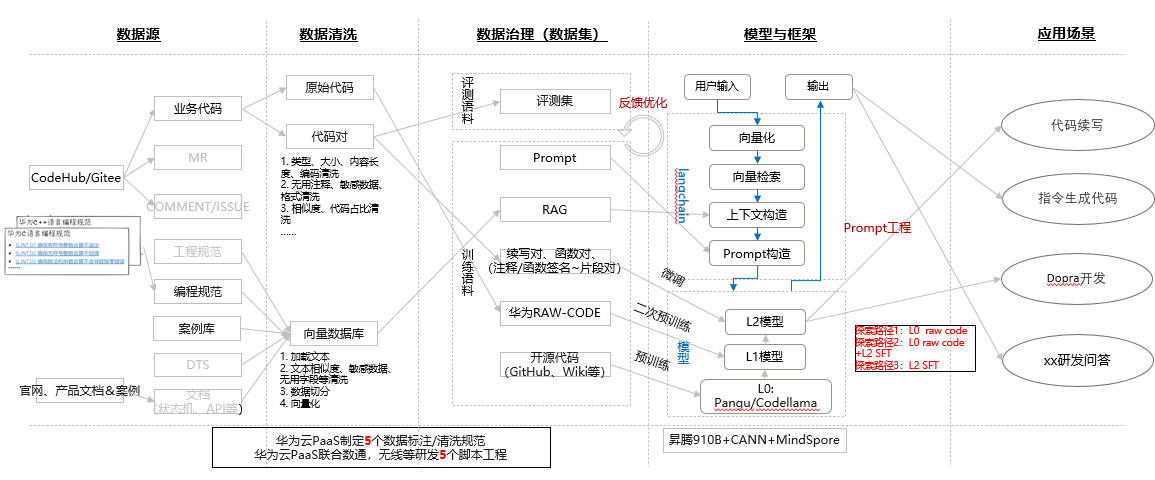
华为云PaaS大模型团队为了提升研发迭代的反馈速度,设立了一系列规定。这包括5项数据标注和清洗的标准,以及5个脚本工程项目。这些规范和项目覆盖了从最初训练数据到模型全自动操作的整个过程。从准备和清洗数据,到训练、评估和部署,每个环节都有详细的规范来指导研发工作,确保其顺利进行。
训练流程进展
在训练流水线上,五个脚本工具获得了业务专家的肯定并得以实施,包括数据清洗工具和SFT提取工具等。同时,对训练语料的详细信息也进行了明确。在L1阶段,对30亿条华为语料库的数据进行了清洗,覆盖了超过十个产品线,从而提升了业务代码的基础能力。这些步骤使得模型训练逐渐趋向完善。
模型应用问题
模型训练取得了一些成效,有助于减轻知识不足的问题,同时也能降低编译和运行错误。然而,模型更新频繁且涉及广泛领域,实际应用时还需参照相关手册。这表明模型尚不能独立完成复杂的产业代码研发任务,通常还需借助人工查阅资料。

未来趋势探讨
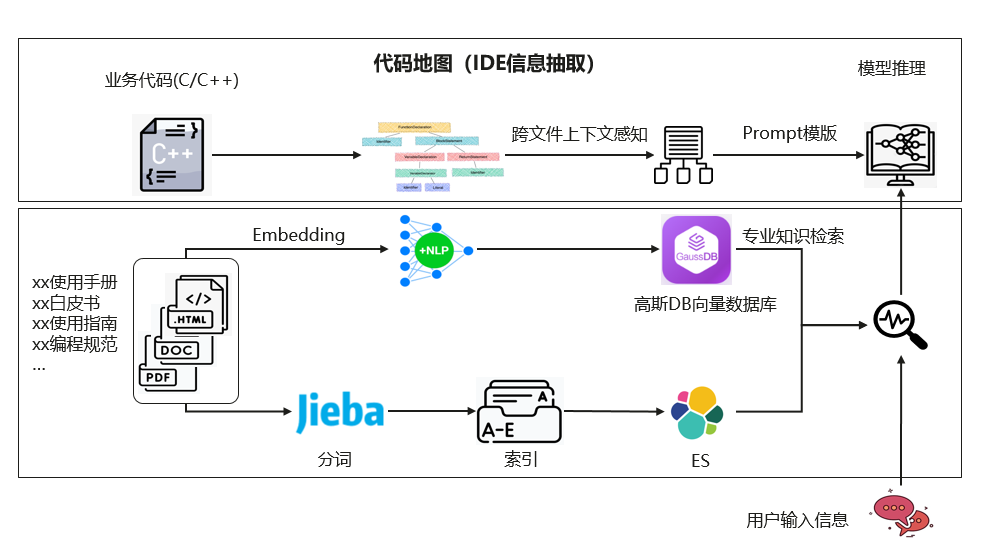
RAG方案强调自动提取信息和识别项目上下文的能力,这能有效提升大型模型生成代码的准确性。然而,华为云PaaS的大模型持续进步,那么,这些模型是否有一天能完全替代程序员?欢迎各位在评论区发表你们的观点。同时,别忘了点赞和转发这篇文章。